 Site Explorer
Site Explorer Keyword tool
Keyword tool Google Algorithm Changes
Google Algorithm Changes
The relationship between JavaScript and SEO started a long time ago and has been a highly debated topic in the virtual world, mostly in the SEO circles. Creating websites using JavaScript to feature content was a big hit back in the days. Many developers used this technique, with some lacking knowledge on whether search engines can parse and understand that content.
Along the way, Google changed its methodology and standpoint regarding JavaScript. Everybody started to doubt whether search engines, like Google, are able to crawl JavaScript. And that was the wrong question to ask. The better question to ask is can search engines parse and understand the content rendered by Javascript? In other words, can Google rank your website if it’s made in JavaScript?

Before starting to answer this question, we need to get some things straight. First, we should talk about how JavaScript works and how it is implemented, then understand how a website using JavaScript can be properly crawled and indexed, then ranked and if search engines can do all those actions for a website using JS code.
- What is JavaScript and How Does it Work?
- Crawling. Indexing. Ranking – The Three Musketeers of SEO
- How Can You Find & Fix All Possible SEO Issues on JavaScript Websites?
- Googlebot vs. Caffeine in the JavaScript Rendering Process
- How Javascript Affects SEO
- How to Make Your Javascript SEO-Friendly
- Conclusion
1. What is JavaScript and How Does it Work?
JavaScript is one of the most popular programming languages to develop websites. It uses frameworks to create interactive web pages by controlling the behavior of different elements on the page.
Initially, JS frameworks were implemented client-side (front-end) only in browsers, but now the code is embedded in other host software, such as server-side (back-end) in web servers and databases, which will save you from a lot of trouble and pain. The problems started when JavaScript implementation relied only on client-side rendering.
If JavaScript frameworks have server-side rendering, you’ve already solved the problem before it even arises. To understand better exactly why problems appear and how can you avoid them, it is important to have some basic knowledge on how search engines work. For that, we need to establish the phases of the information retrieval process: crawling, indexing and ranking.
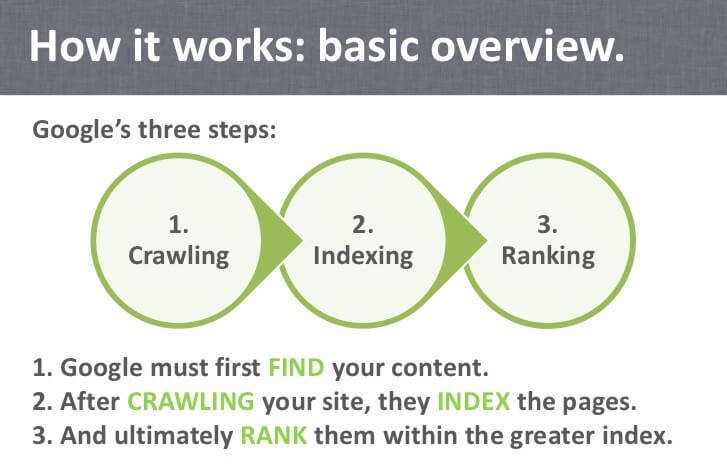
2. Crawling. Indexing. Ranking – The Three Musketeers of SEO
When we talk about Javascript and search engine optimization we need to look at the first two processes: crawling and indexing. Ranking comes afterward.
www.slideshare.net/ryanspoon
The crawling phase is all about discovery. The process is really complicated and uses software programs called spiders (or web crawlers). Googlebot is, maybe, the most popular crawler.
The crawlers start by fetching web pages and then follow the links on the page, fetch those pages and follow the links on those pages and so on, up to the point where pages are indexed. For this method, the crawler uses a parsing module, which does not render pages but only analyzes the source code and extracts any URLs found in the <a href=”…”> script. Crawlers can validate hyperlinks and HTML code.
An important thing to keep in mind is the fact that when you perform a search on Google, you are not searching the web, but on Google’s index of the web. The index is created by all the pages during the crawl process.
You can help Google and tell the crawler which pages to crawl and which not to crawl. A “robots.txt” file tells search engines whether they can access and crawl your site or just some parts. Using this method, you give Googlebot access to the code data. You should use the robots.txt file to show Google exactly what you want your user to see, because otherwise, you may have pages that will be accessed and don’t want to be indexed. Using this tool, you’ll be able to block or manage various crawlers. Check your robots.txt file to avoid errors and ranking drops. Nowadays, most robots.txt files include the XML sitemap address that increases the crawl speed of bots, which comes as an advantage for your website.
In the crawling process, Googlebot has the main role. On the other side, in the indexing process, Caffeine is indexing infrastructure and has the main role.
The indexing phase is all about analyzing the URL and understanding the content and its relevance. The indexer also tries to render the pages and execute JavaScript with a web rendering service (WRS). You can find out exactly how WRS sees your page if you go to Search Console and use the Fetch and Render feature.
| Client-side analytics may not provide a full or accurate representation of Googlebot and WRS activity on your site. Use Search Console to monitor Googlebot and WRS activity and feedback on your site. | |
| Google Developers | |
Practically, these two phases work together:
- The crawler sends what it finds to the indexer;
- The indexer feeds more URLs to the crawler. And as a bonus, it prioritizes the URLs based on their high value.
The whole concept of the relationship between crawl and index is very well explained by Matt Cutts in the “How Search Works” video:
Once this stage is complete and no errors are found in the Search Console, the ranking process should begin. At this point, the webmaster and SEO experts must put effort into offering quality content, optimizing the website, earning and building valuable links following the quality guidelines from Google. Also, it is very important that the people responsible for this process be informed of the Rater Guidelines.
3. How Can You Find & Fix All Possible SEO Issues on JavaScript Websites?
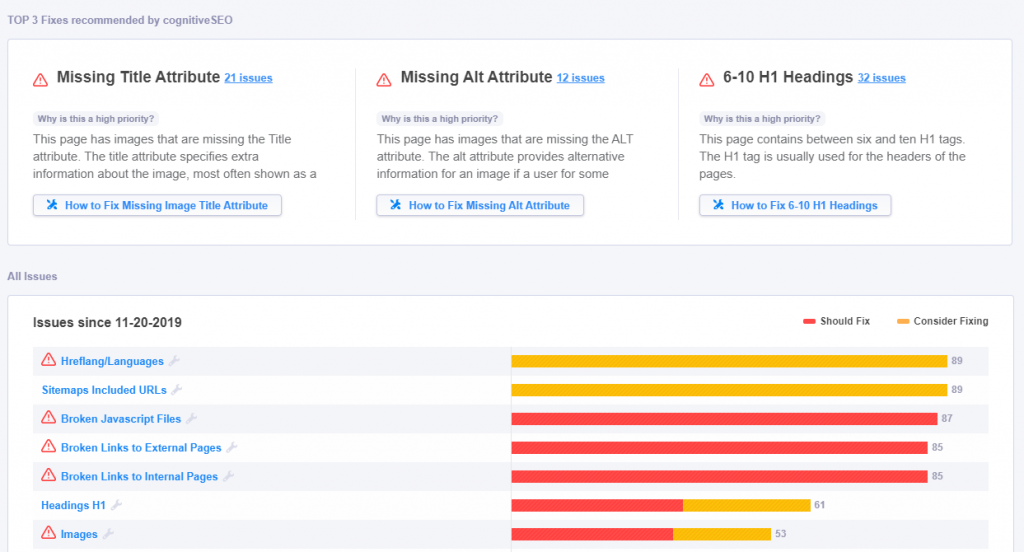
cognitiveSEO’s Site Audit analyzes the technical health of your JavaScript website and helps you detect all the weak points of your website before your users do, giving you a competitive advantage on the competitive market we are swimming in. The SEO Audit Tool crawls all the pages it finds on a website, be it JavaScript or not, regardless of the size of your website, and provides a fully customized set of data easy to comprehend and visualize.
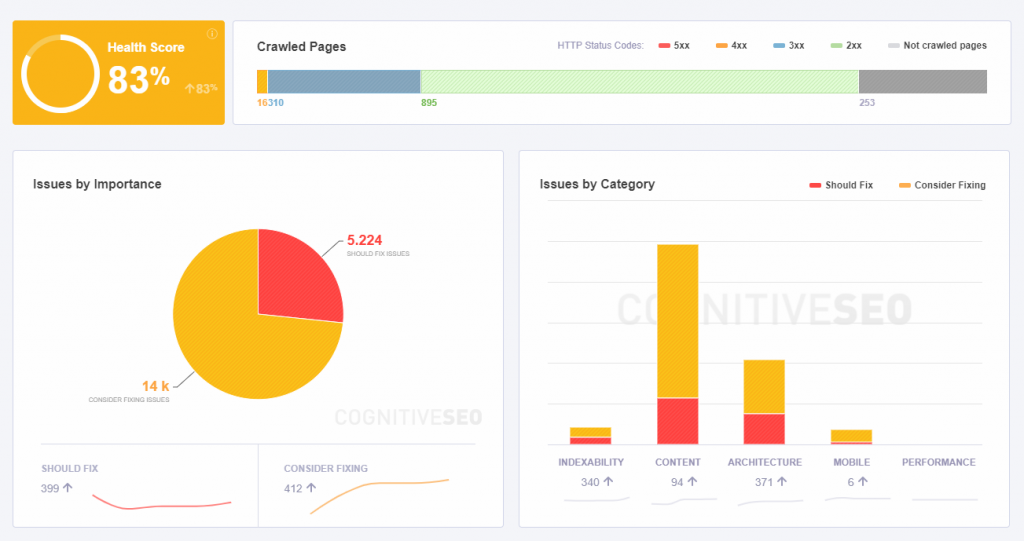
The truth is that with the ever-evolving search engine algorithms you need an efficient solution to keep your rankings safe. And cognitiveSEO does exactly that: it lets you know all the issues that might prevent your online business from getting the organic traffic and the high rankings you deserve.

Performing a complete JavaSscript website audit will give you a deeper understanding of why your site is not generating the organic traffic you think it should or why your sales and conversions are not improving. This kind of website audit gives you a much wider array of SEO items to look at and can analyze issues of all types that might prevent you from reaching your best possible ranking.
4. Googlebot vs. Caffeine in the JavaScript Rendering Process
All the problems began when people started confusing Googlebot (used in the crawling process) with Caffeine (used in the indexing process). Barry Adams talked about the confusion between these two. There’s even a thread on Twitter about it:
The use of 'Googlebot' in there confuses me. The crawler doesn't render, does it? Caffeine is where pages are rendered?
— 🛠 Barry Adams ⌨️ (@badams) August 5, 2017
The explanation is quite simple: the crawler doesn’t render content, the indexer does that. The crawler fetches the content. People say the crawler helps Google to index the content, which is misleading. And because of that the confusion developers and SEOs ask if Googlebot can crawl and index JavaScript, and we tend to say “yes”. Google can render JavaScript, extracts links from it and ranks those pages. We think of Google as a whole, which includes multiple processes (it fetches and then renders). Also, you can read more about Google’s dynamic rendering here.
Even if it is a little bit overwhelming to understand how the process of crawling and indexing is connected, it is easier to use JavaScript. We can see that Google has tried lots of time to make a lot of improvements and crawl all of our website’s pages.
It has lots of guide on how search engine optimization works, how developers should design websites and how content writers should create white-hat content. That is how the crawl budget term took birth.
5. How Javascript Affects SEO
JavaScript means more loading time speed and faster server load (code functions run immediately instead of waiting for the server to answer), easier implementation, richer interfaces and higher versatility (can be used in a huge variety of applications). But, JavaScript SEO brings some problems along the way. Lots of webmasters fail to optimize the content that uses JavaScript code.
So, the question that pops out is: Does it matter that not the crawler takes care of JavaScript, but the indexer? Is it important for the webmaster to know such things? Well, the answer, in this case, is yes, of course. It is very important for them to know the difference in case of errors. They should know how to resolve them and get the outcome they desire, that is Google ranking JavaScript pages.
Now, you can understand that knowing how search works, how a website is created, and the relationship between JavaScript and SEO. We can ask the right questions. Because now we have the correct answers, also.
- “Does Google crawl JavaScript?” The answer is more and more.
- “Does Google index JavaScript?” The answer is yes.
- “Should I use JavaScript?” The answer is it depends.
JS website is indexed and ranked. We’ve learned things the hard way until now. We know that making it easier for Google to understand the generated content is the best approach. To help Google rank content that uses JavaScript, you need tools and plugins to make it SEO-friendly. When we make our content easy to discover, and easy to evaluate, we are rewarded with better rankings in SERPs.
Even if JavaScript has some limitations and Google has some issues with it, most of the problems these websites have, are a result of bad implementation, not Google’s inability to deal with JavaScript.
6. How to Make Your Javascript SEO-Friendly
Back in 2009, Google recommended the AJAX crawling, which had changed in 2015, saying they no longer supported that proposal. In the beginning, search engines were not able to access content from AJAX based websites and that caused real problems. That basically meant the system couldn’t render and understand the page that was using JavaScript for generating dynamic content, therefore the website and user suffered from this. At that time, there were lots of guidelines to help webmasters index those pages.
| Historically, AJAX applications have been difficult for search engines to process because AJAX content is produced dynamically by the browser and thus not visible to crawlers. | |
| google developers | |
In 2015, 6 years later, Google deprecated their AJAX crawling system and things have changed. The Technical Webmaster Guidelines show that they’re not blocking Googlebot from crawling JS or CSS files and they manage to render and understand web pages.
| Today, as long as you’re not blocking Googlebot from crawling your JavaScript or CSS files, we are generally able to render and understand your web pages like modern browsers. | |
| Google Developers | |
And there were other problems that needed to be solved. Some webmasters that were using JS framework had web servers that served a pre-rendered page, which shouldn’t normally happen. Pre-rendering pages should follow the progressive enhancement guidelines and have benefits for the user. In another case, it is very important that the content sent to Googlebot matches the content served to the user, both how it looks and how it interacts. Basically, when Googlebot crawls the page, it should see the same content the user sees. Having different content means cloaking, and it is against Google’s quality guidelines.
The progressive enhancement guidelines say that the best approach for building a site’s structure is to use only HTML, and after that play with AJAX for the appearance and interface of the website. In this case, you are insured, because Googlebot will see the HTML and the user will benefit from the AJAX looks.
The JS code issues can be cured with the help of tools. There are a lot of examples and solutions. JavaScript can be crawled by search engines if, for example, you use Prerender, BromBone, Angular JS SEO (which is Google’s own JavaScript MVW framework), Backbone JS SEO, SEO.JS or other frameworks like React and single page applications (SPA) and progressive web apps.
To put it simply, when Google is indexing a web page, it is reading the templates and not the data. That’s why it is necessary to write codes for the server that will send a version of the site (that does not have JavaScript) to Google. In the client-rendered JavaScript, links were always a problem, as we never knew if Google was able to follow the links to access the content.
Google confirmed another change that reflects AJAX. It started with the decision of deprecating their AJAX crawling system, and Roey Skif asked John Mueller on Twitter about the Fetch as Google the hash bang URLs. Then he tested the impact of this change. He saw a lot of blocked resources that were completely different on the hashbang URLs, and that wasn’t aware of them.
@JohnMu Is the ability to fetch & render hash bang URL's via the GSC is something relatively new? From what I can recall, in the past it wasn't functioning
— Roey Skif (@roeyskif) February 27, 2018
It is true, now Google is supporting hashbang URLs, URLS that have the #! in them in (it stopped doing that in March 30, 2014). This is an example of a link of such: http://www.example.com/bla/#!/bla/. The nice part is you can use Fetch as Google for AJAX hash bang’s URLs.
Google recommends you to use their Fetch as Google tool to allow the Googlebot to crawl your JavaScript. Search Console offers lots of information regarding your website. You have two sections entirely dedicated to Crawl and Index Status:
Another thing you could do, besides using Fetch as Google, is to check and test your robots.txt file from the Search Console, too. The Google Webmaster Tool robots tester allows you to check each line and see each crawler and what access it has on your website. If you take a look at the next screenshot you can see how it works:
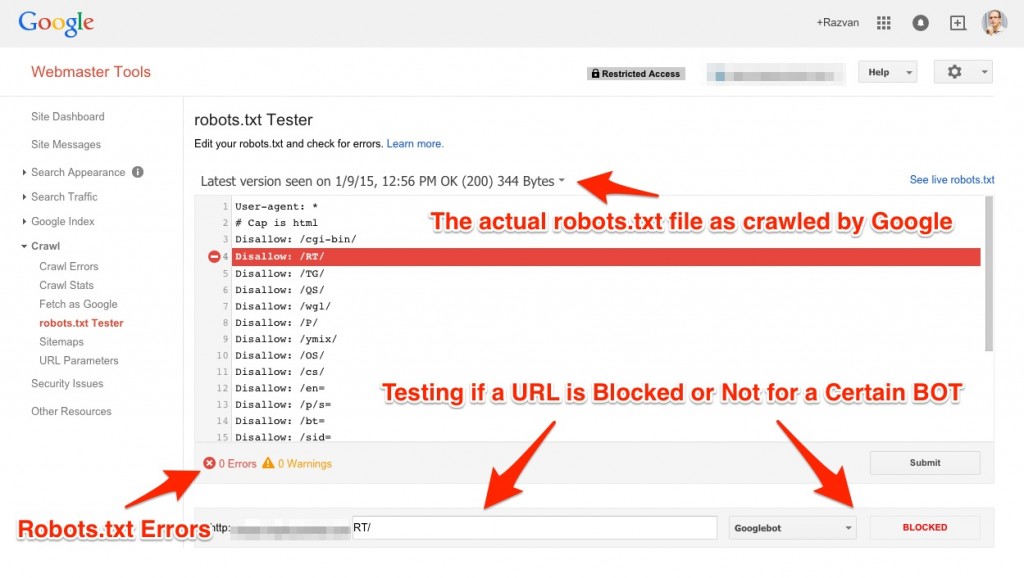
Conclusion
Today’s article focused on technical SEO and mostly targeted developers and SEO experts. JavaScript and SEO is a complex discussion with lots of gaps and misunderstandings, that need further explanation to get things straight once and for all.
The information retrieval process includes crawling, indexing and rankings. You surely heard of them before, but what you didn’t know is that lots of people are confused on how crawling and indexing work together and what each process does. We’ve seen that in the crawling phase the website is fetched, then in the indexing phase the site is rendered. Googlebot (the crawler) fetches the website and Caffeine (the indexer) renders the content. The problem started here when most people confused these two and said that the crawler helps Google to index the website.
Developers should know the difference between Googlebot and Caffeine and what each one of them does in order to use JavaScript in a friendly relationship with SEO. JavaScript had a lot of advantages, but SEO friendly is not one of them and can be hard to achieve.
We know that a JavaScript website’s content is indexed and ranked. But the harsh truth is that it’s done almost reluctantly. In order to have relevant content ranked in Google and achieve great success in organic search, you have to offer the content and links in plain HTML to search engines. In the end, efficiency is what matters, making these 3 processes as easy as possible: crawl, index, and rank your web pages.



Hi guys.Beautiful technical blogs. Thank you for the amazing topics.
Hi Niko!
Thank you. Expecting you back for our next amazing topics.
Hi, this article is inspired on the one written by Barry Adams in August 2017..
Thanks for the feedback, Bart!
Barry’s article is indeed great and it tackles a similar topic; yet, the approaches along with the main points of interest are different.
Thanks you for the info. It helps me out
Glad to hear that, Bhumi. Good luck!
I guess it’s first so in-depth article on JavaScript SEO. Thanks, Andreea!
Hi Akash,
Thank you. Let us know if there are other topics you might be interested in.
Thank you for this article. This makes the Javascript vs. SEO discussions I’ve had with several webdevelopers much more efficient. By sending this article, we can skip a lot of discussion and explaining in the beginning. 😉
Hi Tom,
You’re very welcome. Glad we had the chance to help you. Good luck!
This is a very interesting and informative article on a topic few people thought about and written. You thoroughly explored the possibilities of what Google search engine can do with JS and what it can not. But it certainly makes website load faster, which is excellent for SEO.
Hi Cathy,
You are perfectly right. Hope more people will understand that now.
I’m going to work on this now. While the subject of this article to me is a bit boring, yet necessary, I read it all because of how nice you have your website and fonts laid out. .
Hi Steven,
Thank you so much for the feedback. We’ll come with new interesting topics in the future and make all of them better even if the topic is boring 🙂
thanks Andreea for sharing such great information with us. it will be very helpful for newbies like us.
Hi Andreea!
Well written article and I hope the discussion in this area keep going as JS, AJAX is a common problem in SEO.
However, I have a question (or maybe an idea).
How if we served two different sites?
One for Users (human) and another one is for Bot (Such as GoogleBot, etc.).
It is in the same IP, same subnet.
No different content. 100% exact the same.
For User (human using browser) we served a client-side rendered JS. But for Bot, we served the second version of the web which is server-side rendered.
What is your concern about this?
Thank you Andreea!
Hi Hans,
If they are identical and if the final version is rendered in browser using HTML, there is no point in having two versions of the same site. Ideally would be to have just one.
Could you tell me what is the reason for your question?
Good luck!
I completely agree that its one of the those topic who never thought of written and explore so many things about the co relation between javascript and seo.
As i am in javascript i have to keep in mind that the webpages that i have created should be crawled so that they can rank.
Really wonderful article Andreea i must say..
Thanks for the explanation, but still there’s a lot of confusion in me as I’m not so technical savvy guy. I’m considering to copy protect my site by using JavaScript, ie. preventing mouse right click and browser Inspect function.
Does it matter for my SEO effort or the question, thus confusion, is not relevant at all?
As far as I understand it Java and Javascript is 2 different thing.
Hi Andrea,
Nevermind the question. Even for such protection, we still can see the source with, like using F12 in Chrome browser. I think I now understand that as long as Search Engine can see the HTML content without having to render the Javascript first, it wouldn’t matter… a lot… or at all…
Correct?
Very technical but well explained.
Nice Blog… JavaScript is implemented by many websites but again as you said, if the optimization is on right path then nothing can beat to rank on search engines.
Thank You !