 Site Explorer
Site Explorer Keyword tool
Keyword tool Google Algorithm Changes
Google Algorithm Changes
Intentional or unintentional, be it plagiarism or bad technical implementation, duplicate content is an issue that is affecting millions of websites around the web. If you’ve wondered what content duplication is exactly and how it affects SEO and Google rankings, then you’re in the right place.
Whether you think your site is affected by this issue or just want to learn about it, in this article you will find everything you need to know about duplicate content. From what it is to how you can fix it in specific cases, here you have it all, so keep reading.

- What Is Duplicate Content
- How Google Handles Duplicate Content
- The Myth of the Duplicate Content Penalty
- Why Doesn’t Google Like Duplicate & Very Similar Content?
- How Much Copy/Paste Is Considered Duplicate Content
- The Problems Caused by Duplicate Content
- Internal Duplicate Content Issues
- External Duplicate Content (Plagiarism)
- How To Identify Duplicate Content Issues
- How to Fix Duplicate Content Issues
1. What Is Duplicate Content
Duplicate content is content that has been already written by someone, somewhere else. So, if you take a piece of content off one website with the infamous Copy/Paste and then publish it on your website, then you have duplicate content.
Duplicate content has many sides and can be caused by many things, from technical difficulties or unintentional mistakes to deliberate action. Before we get into more technical aspects, we must first understand what content duplication actually is.
On the web, duplicate content is when the same (or very similar) content is found on two different URLs.
Another key thing here to remember is that the content is already indexed on Google. If Google doesn’t have the original version of the copied content in its index, then it can’t really consider it duplicate content, even though it is!
Around 5 years ago, I was actually contemplating scanning old news magazine pages and, using software, turning the images into text and then use it for PBNs or whatever worked at that time. While that might be illegal from a copyright point of view, it should pass Google’s duplication filters even today.
I would actually recommend publications which are moving from print to digital should repurpose old content in their magazines on their websites.
We all know Google likes to see quality content on your site, and not thin content. If you have it but it’s not on Google yet, it still is new and original, so why not take this opportunity? Sure, some news might be irrelevant today, but I’m sure magazines also featured evergreen content such as “How to lose weight fast”.
An article could even be modified into something like How people used to do fitness in the 80s’. You can keep the content identical this way (although a small original introduction might be required).
However, things are a little bit more complex than that. There’s a big discussion on what exactly makes for duplicate content in Google’s eyes. Is a quote duplicate content?
Will my site be affected if I publish someone else’s content but cite the source?

Also, there isn’t one single solution for fixing duplicate content issues. Why? Because there are very many scenarios. There are multiple solutions and one of them might be better than the other. There are many things to be discussed and, hopefully, by the end of this article you’ll have all your questions answered.
However, we must first get some other things clear to better understand the nature of duplicate content. Then we will analyze different scenarios and give solutions for each and every one of them.
2. How Google Handles Duplicate Content
There’s a lot of content out there in the world. Compared to that, Google knows only about a small part of it. To be able to truly say if the content on your site has been copied, Google would have to know every piece of paper that has ever been written, which is impossible.
When you publish something on your website, it takes a while for Google to crawl and index it. If your site is popular and you publish content often, Google will crawl it more often. This means it can index the content sooner.
If you publish rarely, Google will probably not crawl your site so often and it might not index the content very quickly. Once a piece of content is indexed, Google can then relate other content to it to see if it’s duplicate or not.
The date of the index is a good reference source for which content was the original version.
So what happens when Google identifies a piece of content as duplicate? Well, it has 2 choices:
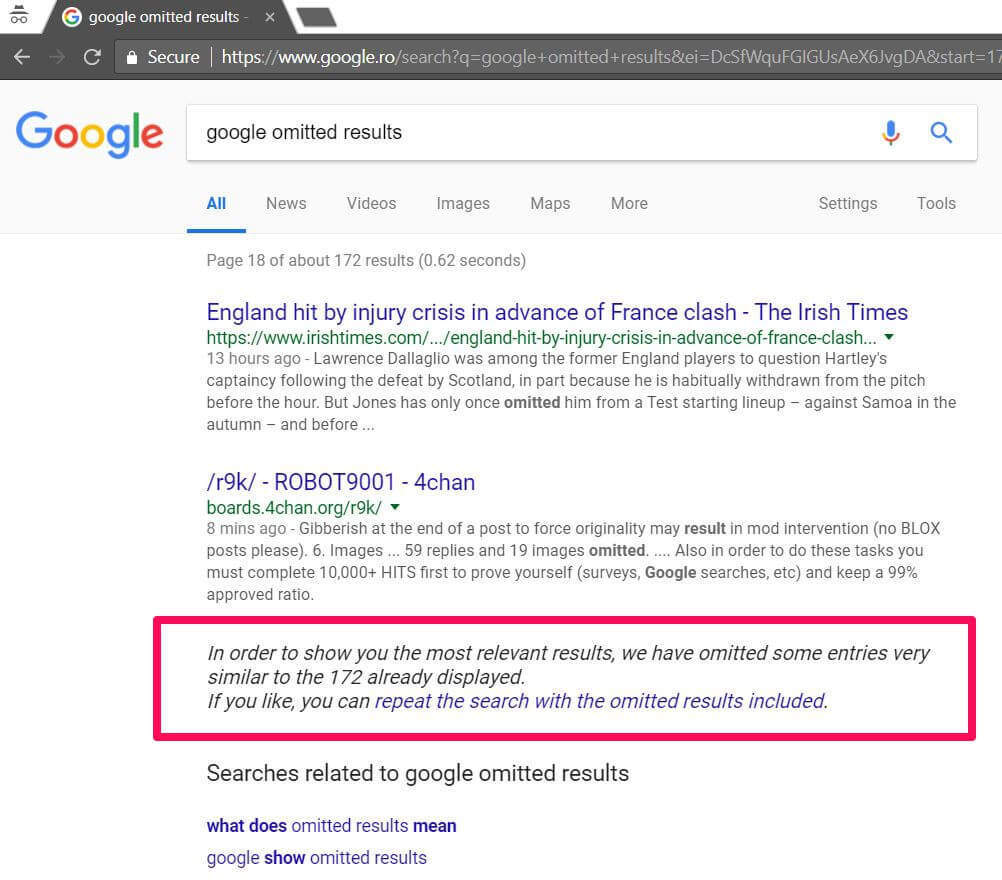
- Display it: Yes, Google might choose to display duplicate content in its search results if it finds it to be actually relevant to a user. A good example might be news publications making the same statements over and over again when something happens.
- Don’t display it: Google throws your content into something often called Google Omitted Results. If you SPAM the web all the time, it might even consider not indexing your site anymore.
3. The Myth of the Duplicate Content Penalty
Will you be penalized for duplicate content? No.
Is duplicate content hurting your site? Well, that’s another story.
Because Google doesn’t like duplicate content very much, people have assumed that it’s a bad practice which gets punished by Google. With a Penalty!
Despite popular belief and although content duplicate does cause issues, there’s no such thing as a duplicate content penalty!
At least not in the same way that we have other penalties, be them manual or algorithmic. Or, at least that’s what Gary Illyes said in a tweet.
DYK Google doesn’t have a duplicate content penalty, but having many URLs serving the same content burns crawl budget and may dilute signals pic.twitter.com/3sW4PU8hTi
— Gary “鯨理” Illyes (@methode) February 13, 2017
This comes in contradiction with Google’s official page on duplicate content on the webmaster guidelines which states that:
“In the rare cases in which Google perceives that duplicate content may be shown with intent to manipulate our rankings and deceive our users, we’ll also make appropriate adjustments in the indexing and ranking of the sites involved. As a result, the ranking of the site may suffer, or the site might be removed entirely from the Google index, in which case it will no longer appear in search results.” – Google
So while there’s no duplicate content penalty, if you ‘try to manipulate search results’ you might end up losing rankings or even getting deindexed. Here’s Google at its best again, contradicting itself, at least a little bit.
However, I tend to take Gary’s word for granted. Duplicate content isn’t something that you should avoid just because Google might hit you in the head. Also, Google won’t hit you just because you have duplicate content.

It’s a different story with those who use content scrapers, deliberately steal content and try to get it ranked or use mass content syndication only for links. It’s not only about content duplication but actually about stealing content and filling the internet up with garbage.
The fact that there’s just so much ‘innocent’ duplicate content out there makes it even harder for Google to detect the evil-doers with a 100% success rate.
But even though Google won’t penalize you, it doesn’t mean that duplicate content can’t affect your website in a negative way.
Talking about duplicate content penalties, here’s what is written in the Google Search Quality Evaluator Guidelines from March 2017:
The Lowest rating is appropriate if all or almost all of the MC (main content) on the page is copied with little or no time, effort, expertise, manual curation, or added value for users. Such pages should be rated Lowest, even if the page assigns credit for the content to another source.
Also, you can check out the video below where Andrey Lipattsev, senior Google search quality strategist, repeated and said content duplication penalty doesn’t exist and also that:
- Google rewards unique content and correlates it with added value;
- The duplicate content is filtered;
- Google wants to find new content and duplicates slows the search engine down;
- If you want Google to quickly discover your new content, you should send XML sitemaps;
- What the search engine wants us to do is to concentrate signals in canonical documents, and optimize those canonical pages so they are better for users;
- It is not duplicate content that is hurting your ranking, but the lack of unique content.
Here’s even more about the duplicate content penalty.
4. Why Doesn’t Google Like Duplicate & Very Similar Content?
Well, the answer to that is very simple:
When you search something on Google, would you like to see the exact same thing 10 times? Of course not! You want different products, so that you may choose. You want different opinions, so that you can form your own.
Google wants to avoid SPAM and useless overload of its index and servers. It wants to serve its users the best content.
As a general rule of thumb, Google tries to display only 1 version of the same content.
However, sometimes, Google fails to do this and multiple or very similar versions of the same pages, many times even from the exact same website get shown.
For example, in Romania, the biggest eCommerce website, eMAG, generates pages dynamically from nearly all the searches that happen on their site. In the following image, you can see 3 top listings for keyword, keyword plural and keyword + preposition. All of these were searched internally on eMAG’s website so they automatically generated these pages and sent them to the index.
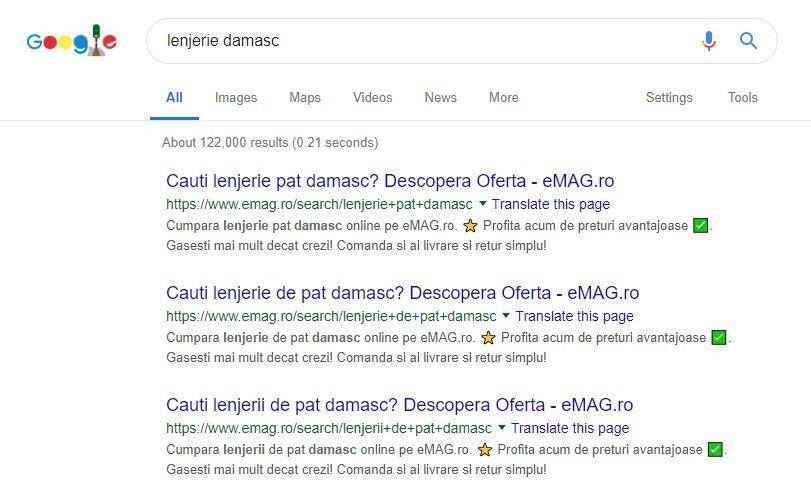
Romanian site featuring 3 duplicate pages in Google search for “damasc bed linen”
You can see the titles & descriptions are very similar and the content on those pages is identical.
Now this is a very smart move from this eCommerce site. Normally, Google shouldn’t allow this to happen. Multiple complaints are emerging in the Romanian eComm community regarding this issue but it seems to keep going (some requests even reached John Mueller).
Although I highly doubt it, it is possible that those results are actually the most relevant. But this doesn’t happen for every keyword out there. Some keyword searches are unique and, most of the time, Google only displays one page from eMAG’s website on the first page.
In my opinion, although this site could canonicalize these versions to a single page, it’s not their fault that they get 3 top listings. It’s Google’s job to rank the pages, not theirs.
This is a classic example of duplicate content issue. From a user’s perspective, this might not be a very good thing. Maybe the user wants to see other websites. Maybe they’ve had a bad experience with the site in the past. Maybe they just want to see if it’s cheaper somewhere else.
Google is still trying to figure out ways to detect when this is an issue and when not. It’s not quite there, but it’s getting better and better.
I’ve encountered some queries where the first 3 pages were all occupied by eMAG results. I can tell you, it’s a scary sight! I highly doubt that they were the only ones selling that type of product, because eMAG is actually a retailer. They sell other people’s products and most of them have their own websites.
5. How Much Copy/Paste Is Considered Duplicate Content (What About Quotes?)
According to Matt Cutts, about 25-30% of the entire internet is made up of duplicate content. That figure might have changed in recent years, since the video is pretty old. Considering the expansion of the internet and the growing number of new websites (especially eCommerce ones, where content duplication is thriving), it has likely increased.
So what we get from the video above is that not all duplicate content is bad. Sometimes people quote other people for a reason. They bring quality to their content by doing that and it isn’t something bad.
In essence, think about it like this:
Duplicate content is when content is identical or very similar to the original source.
Now of course, very similar can be interpreted. But that’s not the point. If you’re thinking about these numbers, then you’re obviously up to something bad. If you’ve contemplated deliberately copying/stealing some content to claim it as your own, then it’s duplicate content. You can also get into legal copyright issues.
A popular type of duplicate content that is harmless are eCommerce sites product descriptions.
Either because they’re lazy or they have so many products to list, eCommerce sites owners and editors simply copy paste product descriptions. This creates a ton of duplicate content, but users might like to still see it on the web because of different prices or services quality.
What ultimately sells a product though is its copy. So don’t just list a bunch of technical specifications. Write a story that sells.
Many eCommerce website owners are complaining that other websites are stealing their description content. As long as they don’t outrank you, I’d see it as a good thing. If they outrank you, simply sue them due to copyright. However, make sure that you have an actual basis on which you can sue them. Some technical product specifications aren’t enough.
Another one is boilerplate content. Boilerplate content is content that repeats itself over and over again on multiple pages, such as the header, navigation, footer and sidebar content.
As long as you’re not trying to steal someone else’s content without their permission and claim it as your own, you’re mostly fine with using quotes or rewriting some phrases. However, if your page has 70-80% similarity and you only replace some verbs and subjects with synonyms… that’s not actually quoting.
Did You Know
Google Search Console no longer allows you to see your duplicate content issues. Some time ago, this was possible, but Google ‘let go’ of this old feature.
So how can you know if you have duplicate content issues?
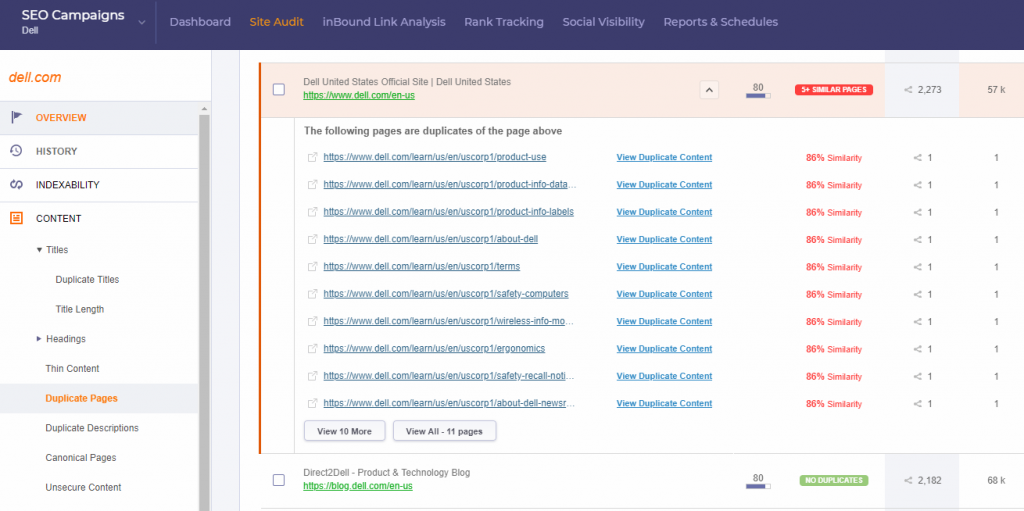
You can use the cognitiveSEO Site Audit Tool for that. The tool has a special section for that, where it automatically identifies any duplicate content issues. Therefore, you can quickly take a look at your duplicate pages, duplicate titles, descriptions, etc.
More than that, the tool has a section that identifies near duplicate pages and tells you the level of similarity between them.
6. The Problems Caused by Duplicate Content
As Gary Illyes pointed above, some of the actual issues caused by duplicate content is that it burns up crawl budget (that especially happens to big sites) and it dilutes link equity, because people will be linking to different pages which hold the same content.
6.1 Burning Crawl Budget
Google has to spend a lot of resources to crawl your website. This includes servers, personnel, internet and electricity bills and many other costs. Although Google’s resources seem unlimited (and probably are), the crawler does stop at some point if a website is very, very big.
If Google crawls your pages and keeps finding the same thing over and over again, it will ‘get bored’ and stop crawling your site.
This might leave important pages uncrawled, so new content or changes might be ignored. Make sure all of your most important pages are crawled and indexed by reducing the number of irrelevant pages your site is feeding to Google.
Since duplicate content is usually generated by dynamic URLs from search filters, it ends up being duplicated not once, but thousands of times, depending on how many filter combinations there are.
One example is the one I gave above with eMAG. In reality, Google filtered a lot more results as doing a search for site:emag.ro + the keyword returns over 40.000 results. Many of those are probably very similar and some might be identical. For example, another variation is keyword + white. However, the landing page doesn’t only list white items, which makes it also irrelevant.
6.2 Link signal dilution
When you get backlinks, they point to a specific URL. That URL gets stronger and stronger the more links it gets. However…
If you have 10 versions of the same page and people can access all of them, different websites might link to different versions of that page.
While this is still helpful for your domain overall, it might not be the best solution for your website or for specific, important pages that you want to rank high.
We’ll talk soon about this issue, what causes it and how to fix it.
6.3 Not SEO Friendly URLs
The URL examples I gave above are rather search engine optimization friendly, but some filters might not look so friendly. We all know Google recommends that you keep your URLs user friendly. Weird long URLs are associated with viruses, malware and scams.
A while ago, we even made a research on thousand of websites and the conclusion was that the more concise the URL, the greater the chance to be higher up.
Example of not friendly URL: https://domain.com/category/default.html?uid=87YHG9347HG387H4G&action=register
Example of friendly URL: https://domain.com/account/register/
Try to keep your URLs short and easy to read, so that they would help and not hurt your sites. For example, people will figure out what those filters mean if you say order=asc&price=500&color=red. But, unless you’re a very big and trustworthy brand, like Google, they won’t be so sure what’s happening if the URL parameter extension is ei=NgfZXLizAuqErwTM6JWIDA (that’s a Google search parameter suffix).
6.4 Bad user experience
As I said previously, sometimes the duplication of a page can result in bad user experience, which will harm your website on the long run.
If you end up ranking a page to the top of Google when it’s not actually relevant, users will notice that immediately (ex. indexing a search page with color xyz when you have no items with that color).
7. Internal Duplicate Content Issues
It’s finally time to list the most popular scenarios of how duplicate content gets created on the web. To check some SEO basics, let’s start with how it happens on websites internally, because it’s by far the most common issue.
7.1 HTTP / HTTPS & WWW / non-WWW
If you have an SSL certificate on your website, then there are two versions of your website. One with HTTP and one with HTTPS.
- http://domain.com
- https://domain.com
They might look very similar, but in Google’s eyes they’re different. First of all, they’re on different URLs. And since it’s the same content, it results in duplicate content. Second, one is secure and the other one is not. It’s a big difference regarding security.
If you’re planning to move your site to a secure URL, make sure to check this HTTP to HTTPS migration guide.
There are also two more versions possible:
- domain.com
- www.domain.com
It’s the same thing as above, whether they’re running on HTTP or HTTPS. Two separate URLs containing the same content. You might not see a big difference between those two, but www is actually a subdomain. You’re just so used to seeing them as the same thing because they display the same content and usually redirect to a single preferred version.
While Google might know how to display a single version on its result pages, most of the time it doesn’t always get the right one.
I’ve encountered this many times. It’s a technical SEO basic thing that every SEO should check, yet very many make this mistake and forget to set a preferred version. On some keywords Google displayed the HTTP version and on some other keywords it displayed the HTTPS version of the same page. Not very consistent.
So how can you fix this?
Solution: To solve this issue, make sure you’re redirecting all the other URL versions to your preferred version. This should be the case not only for the main domain but also for all the other pages. Each page of non-preferred versions should redirect to the proper page’s preferred version:
For example, if your preferred version is https://www.domain.com/page1 then…
- http://domain.com/page1/
- http://www.domain.com/page1/
- https://domain.com/page1/
…should all 301 redirect to https://www.domain.com/page1/
Just in case you’re wondering, a WWW version will help you on the long term if your site gets really big and you want to server cookieless images from a subdomain. If you’re just building your website, use WWW. If you’re already on root domain, leave it like that. The switch isn’t worth the hassle.
You can also set the preferred version from the old Google Search Console:
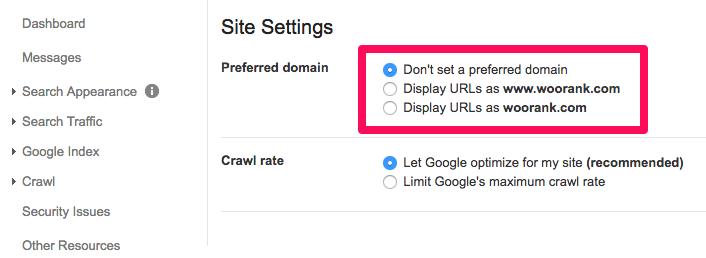
However, 301 redirects are mandatory. Without them, the link signals will be diluted between the 4 versions. Some people might link to you using one of the other variants. Without 301 redirects, you won’t take full advantage of those links and all your previous link building efforts will vanish.
Also, we’re not yet sure of the course the GSC is taking with its new iteration, so it’s unclear if this feature will still be available in the future.
7.2 Hierarchical Product URLs
One common issue that leads to duplicate content is using hierarchical product URLs. What do I mean by this?
Well, let’s say you have an eCommerce store with very many products and categories or a blog with very many posts and categories.
On a hierarchical URL structure, the URLs would look like this:
- https://www.domain.com/store/category/subcategory/product
- https://www.domain.com/blog/category/subcategory/article
At a first look, everything seems fine. The issue arises when you have the same product or article in multiple categories.
Now one solution:
As long as you are 100% certain that your product/article won’t be in two different categories, you’re safe using hierarchical URLs.
For example, if you have a page called services and have multiple unique services with categories and subcategories, there’s no issue in having hierarchical URLs.
- https://www.domain.com/services/digital-marketing/
- https://www.domain.com/services/digital-marketing/seo
- https://www.domain.com/services/digital-marketing/ppc
- https://www.domain.com/services/digital-marketing/email-marketing
- https://www.domain.com/services/website-creation/
- https://www.domain.com/services/website-creation/presentation
- https://www.domain.com/services/website-creation/blog
- https://www.domain.com/services/website-creation/ecommerce
Solution: If you think your articles or products will be in multiple categories, then it’s better to separate post types and taxonomies with their own prefixes:
- https://www.domain.com/store/category/subcategory/
- https://www.domain.com/store/products/product-name/
Category pages can still remain hierarchical as long as a subcategory isn’t found in multiple root categories (one scenario would be /accessories, which can be in multiple categories and subcategories, but it’s only the name that’s the same, while the content is completely different, so it’s not duplicate content).
Another solution would be to specify a main category and then use canonical tags or 301 redirects to the main version, but it’s not such an elegant solution and it can still cause link signal dilution.
Warning: If you do plan on fixing this issue by changing your URL structure, make sure you set the proper 301 redirects! Each old duplicate version should 301 to the final and unique new one.
7.3 URL Variations (Parameters & Session IDs)
One of the most common causes of content duplication are URL variations. Parameters and URL extensions create multiple versions of the same content under different URLs.
They are especially popular on eCommerce websites, but can also be found on other types of sites, such as booking websites, rental services and even blog category pages.
For example, on an eCommerce store, if you have filters to sort items by ascending or descending price, you can get one of these two URLs:
- domain.com/category/subcategory?order=asc
- domain.com/category/subcategory?order=desc
These pages are called faceted pages. A facet is one side of an object with multiple sides. In the example above, the pages are very similar, but instead of being written A to Z they’re written Z to A.
Some people will link to the first variant, but others might link to the second, depending on which filter they were on last. And let’s not forget about the original version without any filters (domain.com/category/subcategory). On top of that, these are only two filters, but there might be a lot more (reviews, relevancy, popularity, etc.).
This results in link signal dilution, making one of every version a little bit stronger, instead of making a single version of that page really strong. Eventually, this will lead to fewer rankings overall.
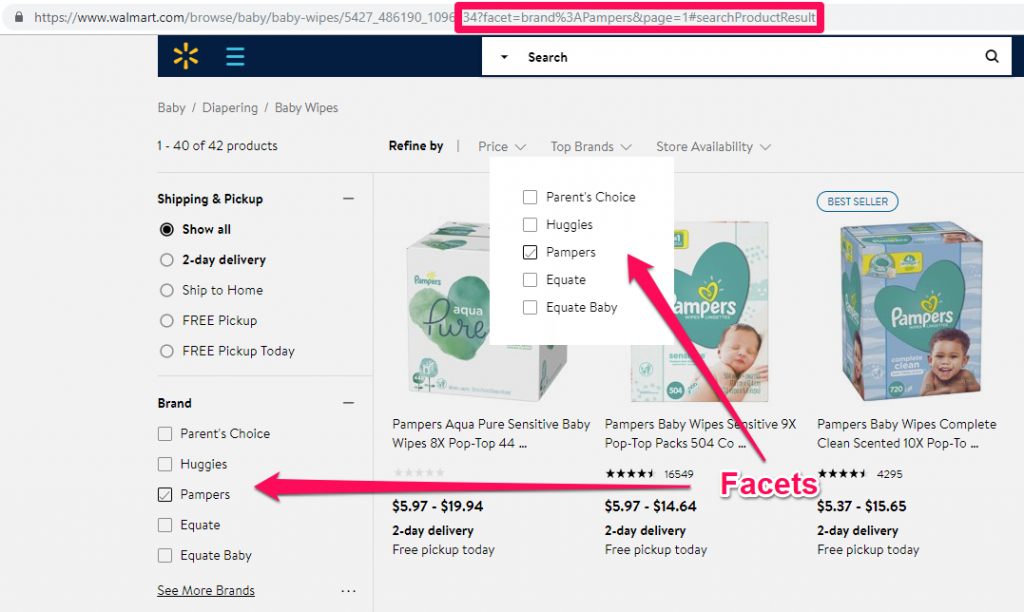
Walmart having brand facets on its baby wipes category
Sure, you might argue that because of pagination, the pages will actually be completely different. That’s true if you have enough products in a category to fill multiple pages.
However, I could also argue that the first page of “?order=desc” is a duplicate of the last page of domain.com/category/subcategory?order=asc and vice versa. One of them is also a duplicate of the main version, unless the main version orders them randomly.
I could also argue that Google doesn’t really care about pagination anymore. In fact, it cares so little that it forgot to tell us that it doesn’t care about them.
Google still recommends using pagination the same way as you did before (either with parameters or subdirectories).
However, you should also make sure now that you properly interlink between these pages and that each page can ‘kind of’ stand on its own. Mihai Aperghis from Vertify asked John Mueller about this and this was his response:
https://youtu.be/1xWLUoa_YIk?t=876
Just because parameters create duplicate content issues it doesn’t mean you should never index any pages that contain parameters.
Sometimes it’s a good idea to index faceted pages, if users are using those filters as keywords in their search queries.
For example, some bad filters which you should not index could be sorting by price as shown above. However, if your users search for “best second hand car under 3000” then filters with price between X and Y might be relevant.
Another popular example are color filters. If you don’t have a specific color scheme for a product but the filter exists, you don’t want to index that. However, if filtering by the color black completely changes the content of the page, then it might be a relevant page to index, especially if your users also use queries such as “black winter coats”.
The examples above are for some general eCommerce store, but try to adapt them to your particular case. For example, if you have a car rental service, people might not necessarily search for color but they might search for diesel, petrol or electric, so you might want to index those.
One thing to mention is that anchor-like extensions & suffixes (#) are not seen as duplicate URLs. Google simply ignores fragments.
Ian Laurie from Portent talks about fixing a HUGE duplicate content issue (links with parameters to contact pages on every page of the site) like this. The solution was to use # instead of ? as an extension to the contact page URL. For some reason, Google completely ignores links with anchors.
However, in this article Ian mentions that he hasn’t even tried rel=canonical to fix the issue. While rel=canonical would probably not harm at all, in this case it might have not been helpful due to the scale of the issue.
Solution: The best solution here is to actually avoid creating duplicate content issues in the first place. Don’t add parameters when it’s not necessary and don’t add parameters when the pages don’t create a unique facet, at least to some extent.
However, if the deed is done, the fix is to either use rel=canonical and canonicalize all the useless facets to the root of the URL or noindex those pages completely. Remember though that Google is the one to decide if it will take the ‘recommendation’ you give through robots.txt or noindex meta tags. This is also applicable to canonical tags, but from my experience, they work pretty well!
Remember to leave the important facets to be indexed (self referencing canonical), especially if they have searches. Make sure to also dynamically generate their titles.
The title of the facet should not keep the same title as the main category page. It should be dynamically generated depending on the filters. So if my category is Smartphones and the title is Best Smartphones You Can Buy in 2019 and the user filters after color and price, then the title of the facet should be something like “Best Blue Smartphones Under $500 You Can Buy in 2019”
7.4 Bad Multilingual Implementation
Another issue that can result in content duplication is a bad hreflang implementation.
Most multilingual websites have a bad hreflang implementation. That’s because most plugins out there implement the hreflang wrong.
Even I use some because I couldn’t find an alternative. I’ll present the issue:
When you have 2 languages and a page is translated to both languages, everything is fine. Each page has 2 hreflang tags pointing correctly to the other version. However, when a page is untranslated, the other language version points to the root of the other language, when it should not exist at all. This basically tells Google that the French language version of domain.com/en/untranslated-page/ is domain.com/fr/, which isn’t true.
Polylang has this issue. I know WPML also had it, but I’m not sure if they’ve addressed it yet.
However, it’s not the hreflang tag itself that causes duplicate content issues, but the links to these pages from the language selector.
The hreflang issue only confuses search engines into which page to display where. It doesn’t cause duplicate content issues. But while some plugins are smarter, others also create the pages and links to those other versions in the menu of the website. Now this is duplicate content.
When the pages aren’t translated, qTranslate (which has been abandoned) creates links to the other variants but lists them as empty or with a warning message saying something like “This language is not available for this page). This creates a flood of empty pages with similar URLs and titles (stolen from the original language) that burn crawl budget and confuse search engines even more.
Now you might think a fix is easy, but merging from one plugin to another isn’t always the easiest thing to do. It takes a lot of time and effort to get it right.
Solution: The simple solution is to not create any links to untranslated variants. If you have 5 languages, a page which is translated to all 5 languages should include the other 4 links in the menu (under the flag drop down let’s say) and also have the appropriate hreflang tags implemented correctly.
However, if you have 5 languages but a particular page is only translated in 2 languages, the flags dropdown should only contain 1 link, to the other page (maybe 2 links to both pages, a self-referencing link isn’t really an issue). Also, only 2 hreflang tags should be present instead of all 5.
If you want to know more about SEO & multilingual websites you should read this post on common hreflang mistakes.
7.5 Indexed Landing Pages for Ads
While it’s good to have landing pages that are focused on conversions everywhere, sometimes they’re not the best for SEO. So it’s a very good idea to create customized pages only for ads.
The thing here is that many times, they are very similar and offer the same content. Why similar and not identical? Well, there can be many reasons. Maybe you have different goals for those pages, or different rules from the advertising platform.
For example, you might only change an image because Adwords rules don’t let you use waist measuring tools when talking about weight loss products. However, when it comes to organic search, that’s not really an issue.
Solution: If your landing pages have been created specifically for ads and provide no SEO value, use a noindex meta tag on them. You can also try to canonicalize them to the very similar version that is actually targeted to organic search.
7.6 Boilerplate Content
Boilerplate content is the content that is found on multiple or every page of your site. Common examples are Headers, Navigation Menus, Footers and Sidebars. These are vital to a site’s functionality. We’re used to them and without them a site would be much harder to navigate.
However, it can sometimes cause duplicate content, for example when there is too little content. If you have only 30 words on 50 different pages, but the header, footer and sidebar have 250 words, then that’s about a 90% similarity. It’s mostly caused by the lack of content rather than the boilerplate.
Solution: Don’t bother too much with it. Just try to keep your pages content rich and unique. If some faucet pages from your filters list too little products, then the boilerplate content will be most of the content. In that case, you want to use the solution mentioned above in the URL Variations section.
It’s also a good idea if you keep it a little bit dynamic. And by dynamic I don’t mean random. It should still be static on each page, just not the same on every page.
For example, Kayak uses a great internal linking strategy in its footer. Instead of displaying the same cities over and over again, it only displays the closest or more relevant ones. So while the homepage displays the most important cities in the US, New York only displays surrounding cities. This is very relevant for the user and Google loves that!
8. External Duplicate Content (Plagiarism)
Duplicate content can occur cross-domains. Again, Google doesn’t want to show its users the same thing 6 times, so it only has to pick one, the original article most of the times.
There are different scenarios where cross-domain content duplication occurs. Let’s take a look at each of them and see if we can come up with some solutions!
8.1 Someone steals your content
Generally, Google tries to reward the original creator of the content. However, sometimes it fails.
Contrary to popular belief, Google might not look at the publication date when trying to determine who was first, because that can be easily changed in the HTML. Instead, it looks at when it first indexed it.
Google figures out who published the content first by looking at when it indexed the first iteration of that content.
People often try to trick Google into thinking they published the content first. This has even happened to us, here at CognitiveSEO. Because we publish rather often, we don’t always bother to tell Google “Hey, look, new content, index it now!”
This means that we let the crawler do its job and get our content whenever it thinks it suitable. But this allows for others to steal the content and index it quicker than us. Automatic blogs using content scapers steal the content and then tells Google to index it immediately.
Sometimes it takes the links as well and then Google is able to figure out the original source if you do internal linking well. But often it strips all links and sometimes even adds links of their own.
Because our domain is authoritative in Google’s eyes and most of those blogs have weak domains, Google figures things out pretty quickly.
But if you have a rather new domain and some other bigger site steals your content and gets it indexed first, then you can’t do much. This happened to me once with my personal blog in Romania. Some guys thought the piece was so awesome they had to steal it. Problem was they didn’t even link to the original source.
Solution: When someone steals your content the best way to protect yourself is to have it indexed first. Get your pages indexed as soon as possible using the Google Search Console.

This might be tricky if you have a huge website. Another thing you can do is to try and block the scrapers from crawling you from within your server. However, they might be using different IPs each time.
You can also file a DMCA report to Google and let them know you don’t agree with your content being stolen/scraped. There are very little chances that this will help, but you never know.
8.2 You steal someone else’s content
Well… I can’t say much about this. You shouldn’t be stealing other people’s content! It should be written somewhere on a Beginners guide to SEO that stealing content is not a content marketing strategy.

In general, having only duplicate content on your website won’t give you great results with search engines. So using content scraping tools and automated blogs isn’t the way to go for SEO.
However, it is not unheard of sites that make a decent living out of scraping content. They usually promote that through ads and social media, but sometimes also get decent search engine traffic, especially when they repost news stories.
This can result in legal action which might close your site and even get you in bigger problems, such as lawsuits and fines. However, if you have permission from the owners to scrape their content, I wouldn’t see an issue with that. We all do what we want, in the end.
While Google considers that there’s no added value for their search engine and tries to reward the original creator whenever possible, you can’t say that a news scarping site is never useful. Maybe a natural disaster warning news reaches some people through that site and saves some lives. You never know.
What if you don’t actually steal their content?
What about those cases in which you really find a piece of content interesting and want to republish it so that your audience can also read it? Or let’s say you publish a guest post on Forbes but also want to share it with your audience on your site?
Well, in that case there’s not really an issue as long as you get approval from the original source.
Solution: It’s not really an issue from an SEO point of view if you publish someone else’s content. However, make sure you have approval for this to not get into any legal issues. They will most probably want a backlink to their original post in 99.9% of the cases.
You can even use a canonical link to the original post. Don’t use a 301 as this will send the people directly to the source, leaving you with no credit at all.
Don’t expect to rank with that content anywhere, especially if your overall domain performance is lower than the original source. That being said, don’t let other big websites repost your content without at least a backlink to your original source in the beginning of the article or, preferably, a full fledged canonical tag in the HTML source.
8.3 Content Curation
Content curation is the process of gathering information relevant to a particular topic or area of interest. I didn’t write that. Wikipedia did.
Curating content rarely leads to duplicate content. The difference between content curation and plagiarism is that in plagiarism, people claim to be the original owner of the content.
However, the definition has its issues, as things can be very nuanced. What if I actually come up with an idea, but I don’t know that someone has written about it before? Is that still plagiarism?
In fact, what did anyone ever really invent? Can you imagine/invent a new color? Even Leonardo Da Vinci probably inspired his helicopter from the maple seed.
This post, for example, is 100% curated content. I’ve gathered the information from around the web and centralized it here. Brian Dean calls this The Skyscraper Technique. While people have done this for ages, he gave it a name and now he’s famous for that.

Skyscraper Technique by Backlinko
However, I didn’t actually steal anything. I’ve gathered the information in my head first and then unloaded it here in this article. I didn’t use copy paste and I didn’t claim to have invented these techniques or methods. I cited people and even linked to them. All I did was put all this information into one place by rewriting it from my own head.
Solution: When you write content using the Skyscraper Technique or by curating content or whatever you want to call it, make sure you don’t copy paste.
Make sure you look at the topic from a new perspective, from a different angle. Make sure you add a personal touch. Make sure you add value. That’s when it’s going to help you reach the top.
8.4 Content Syndication
After web scraping, content syndication is the second most common duplicate content around the web. The difference between these two is that it’s a willful action.
So the question arises! Will syndicating my content over 10-20 sites affect my SEO?

In general, there’s no issue in syndicating content, as long as it’s not your main content generation method (which kind of looks like web scraping).
When syndicating content, it’s a great idea to get a rel=canonical to the original source, or at least a backlink.
Again, Google doesn’t like seeing the same thing over and over again. That’s actually the purpose of the canonical tag, so use it properly!
Solution: Make sure content syndication isn’t your main thing as it might be picked up by Google as scraping content. If you want to syndicate your content, do your best to try to get a canonical tag to the original URL on your site. This will ensure that other sites won’t be able to outrank you.
If rel=canonical isn’t an option, then at least get a backlink and try to get it as close to the beginning as possible.
9. How To Identify Duplicate Content Issues
If you’ve purposely reached this article, then you most probably already have a duplicate content issue. However, what if you don’t know you have one?
Some time ago, this was also possible in the old version of the Google Search Console. Unfortunately, this sections now returns “This report is no longer available here.” In their official statement, Google said that they will ‘let go’ of this old feature.
Image from SerpStat
Well, since that’s no longer available, the CognitiveSEO Site Audit Tool is a great way to easily identify duplicate content issues:
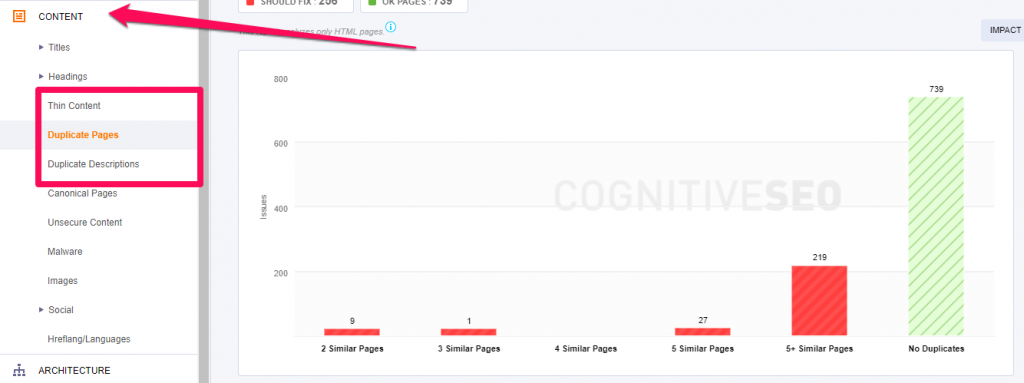
You can take a look at the content duplication or the Title, Heading and Meta Description duplication.
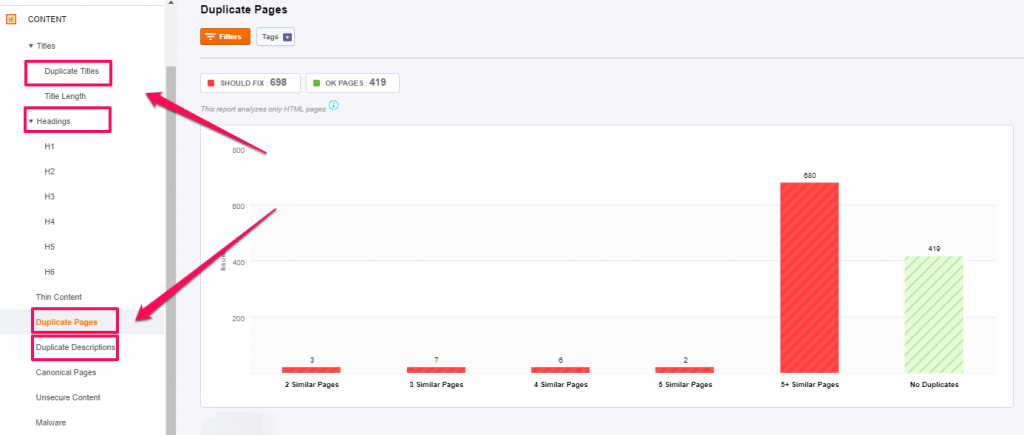
The tool also has an awesome advanced feature that identifies near duplicate pages and tells you the level of similarity between them!
Every page in the tool has hints on how you can fix different issues, so if you’re trying to fix any duplicate content issues, the Site Audit Tool can definitely help you out.
11. How to Get Rid Of or Fix Duplicate Content Issues
In the examples I gave above for each scenario, you’ve seen that there are different solutions, from not indexing the pages to 301 redirects and canonical URL tags.
Let’s take a look at what each solution does so that you may better understand why each one might be better for particular cases. This way, you’ll be able to make the right choice when faced with your unique scenario.
First of all, remember that:
The best way to fix duplicate content is to avoid having it in the first place.
Duplicate content issues can escalate very quickly and can be very difficult to fix. That’s why it’s always a good idea to talk to an SEO specialist before you even launch a webiste. Make sure the specialist gets in contact with the development team. Preventing an illness is always better and cheaper than treating it!
11.1 Using 301 Redirects
The 301 redirect can fix a duplicate content issue. However, this also means that the page will completely vanish and redirect to a new location.
If you users don’t need to access that page, the 301 is the best way of dealing with duplicate content. It passes link equity and Google will always respect it. However, it’s not a good use case for facets, for example, because you want your users to be able to access those pages.
You can use a plugin to 301 redirect or redirect from the .htaccess file if you’re on an Apache server. There are also probably 1,000 other ways of setting up a 301 but you have Google for that.
11.2 Using Canonical Tags (probably best)
The canonical tag has actually been introduced by Google as a solution to content duplication.
Whenever you need users to be able to access those pages from within the website or anywhere else but don’t want to confuse search engines in which page to rank since they might be very similar, then you can use the canonical tag to tell search engines which page should be displayed in the search results.
11.3 Using Noindex
Not indexing some pages can also fix duplicate content issues. However, you have to make sure these pages are actually useless.
A big warning sign that you should not remove them from the index are backlinks. If these pages have backlinks, then a 301 or a canonical tag might be the better choice since they pass link signals.
You can either block the pages from being indexed through your robots.txt file:
User-agent: *
Disallow: /page-you-want-noindex-on/
Or you can add a noindex meta tag directly on the pages you don’t want Google to index:
<meta name=”robots” content=”noindex”>
However, Google will choose to follow or ignore your indications, so make sure you test the effectiveness of your action on your particular case.
11.4 Using a mix of all
Sometimes, you can’t fix them all. You might want to noindex some facets of your filtered pages, while you might want to canonicalize others. In some instances, you might even want to 301 them since they don’t have value anymore. This really depends on your particular case!
An awesome guide on how different duplicate content fixes affect pages and search engines can be found here. This is a screenshot of the table in that article presenting the methods and their effects:
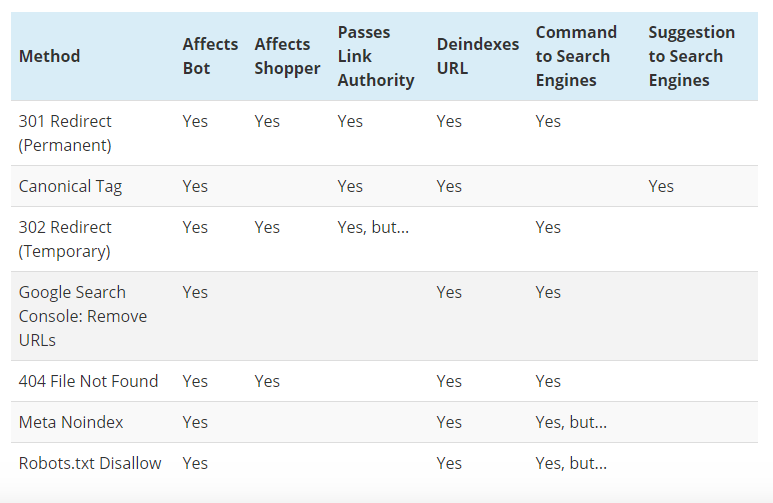
Screenshot from practicalecommerce.com
Conclusion
Duplicate content is an issue affecting millions of websites and approximately 30% of the entire internet! If you’re suffering from duplicate content, hopefully now you know how you can fix it.
We tried to create a complete guide where you can find anything you want about the subject “duplicate content and SEO.” This advanced guide to SEO and duplicate content will surely help you whether you’re doing some technical SEO audits or if you’re planning an online marketing campaign.
Have you encountered content duplication issues in your SEO journey? Let us know in the comments section below!



Hey, buddy 😀
After writing an article I’m using the plagiarism checker before publishing the content.
Hi adrian,
I have always liked your blog and specially in this article i liked how you gave solution after making us realise the problem to which we were not giving attention earlier
This post clear off many of my doubts about content creation and content marketing.
Great Article! Through this post, you have broken the myths that people have in their mind regarding duplicate content. I’m waiting for more articles like this.
Hey awesome article. I will use it to educate my clients 🙂 I don’t have time for own blog.