 Site Explorer
Site Explorer Keyword tool
Keyword tool Google Algorithm Changes
Google Algorithm Changes
eCommerce navigation or faceted navigation in SEO. There are phrases the Gods of SEO themselves squint at when they hear them. Why? Because it involves duplicate content and very big sites. And we all know how difficult that is to fix.
The subject is hard to master and it comes with a lot of confusion on the side. Faceted search or filtered search? What is the difference between facets and filters? Which pages should I index? These are all questions webmasters ask themselves. So prepare for a ‘headachy’ journey as we’ll try to explain a couple of things in this article, such as the difference between filters and facets, which pages you should and shouldn’t index and best practices for different scenarios.

Hopefully, by the end of this article you’ll have understood everything you need to know about how to set up facets for eCommerce websites and how to manage your URL parameters for best SEO results and Google rankings.
Beware: This article is about very advanced stuff and it will twist your brain a little. It can also twist your rankings, in a good way or in a bad way, depending on whether you implement modifications the right way. The best implementation depends on the website and it differs from one case to another. If you don’t know what you’re doing, it’s better to ask for an expert’s opinion!
- Faceted Search vs. Filtered Search: What Is the Difference Between Search and Filters?
- Faceted Search Problems & Challenges
- How Google Handles URL Parameters & How It Affects SEO
- Which URL Parameters to Index & Which Ones to Not
- How to Fix Faceted Search Issues & Have a Good Navigation Structure
1. Faceted Search vs. Filtered Search:
What Is the Difference Between Search and Filters?
It took me myself a long time to figure out this difference. Why? Because I didn’t know what facet means. And I’m not talking about its meaning in eComm, I’m talking about its meaning in general.
So let’s start with that:
A facet is one side of a many-sided thing. Like a gem or a dice. We can also say it’s a particular aspect or feature of something.
Ok, so what does that have to do with filters and search?
Well, in eCommerce, the products of a website are usually split into categories. Sometimes, that’s enough to be able to browse it. However, in cases where there are very many products, it might not be enough.
In order to be able to browse the website efficiently, you’ll have to be able to sort those products according to different attributes. You know, like size, color, weight, etc.
To see only results that match certain criteria, you have to apply something which is known as a filter. A filter can include items that only contain the specified attribute, or it can exclude items that don’t.
Ok, so what does that have to do with facets?
Well, when you apply a filter, you can call each result page returned a facet of the category you’re currently browsing.
There are many websites that try to explain the difference between filters and facets. One explanation is that facets are unique pages and they are extensions to the category pages, while filters are just used to refine item listings.
While that’s true, one thing they seem to get wrong is that facets should be indexed and filters should not be indexed.
In the articles I’ve found (not going to give the names, though) the writers used the following example:
- Dresses
- Going out
- Evening
- View all
- Filter by
- Shipping
- Size
- Price
- Brand
- Brand A
- Brand B
- Brand C
The writers argued that Dresses and Brands are Facets, therefore they should be indexed, while Shipping, Size and Price are filters and should not be indexed.
My counterargument is: What if a lady searches for “evening dresses size M under 400$”?
Now this might be far fetched, but it can very well be the case! The best example I personally know is in the used car industry. People search a lot for things like “used cars under xxx”.
In the following example you can clearly see that Google auto-suggests these types of results:
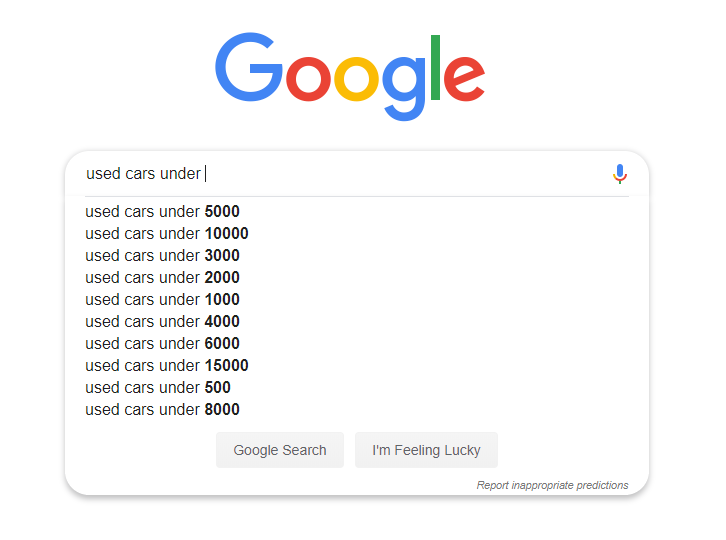
So we can clearly see that people search for these keywords. Let’s do a search for “used cars under 10000” and see what results we get:
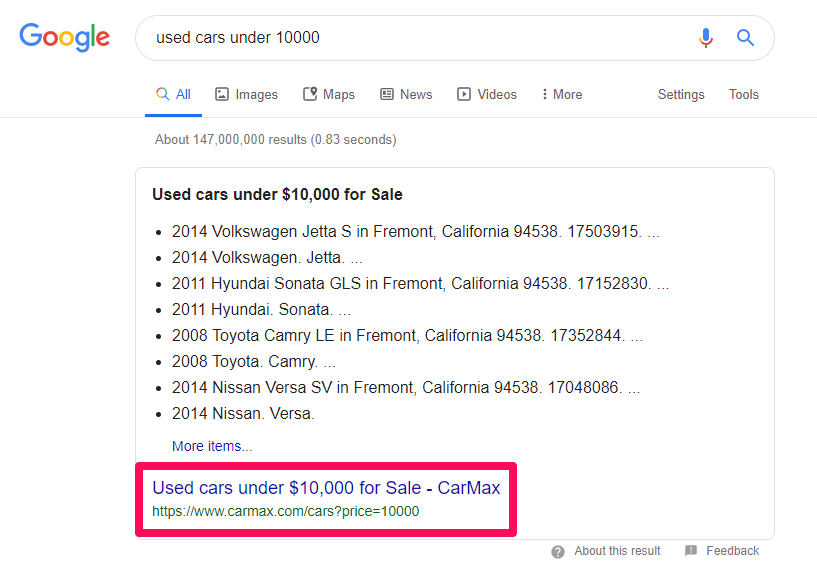
Hmm… interesting. It seems like Google is returning an answer box for this result. This is cool! I can click on More items to get to Carmax.com.
I’ve highlighted the URL above to show which site is ranking in the answer box. Carmax is also ranking #1 so it has multiple positions on Google.
But wait! Is that a URL parameter? Could it be a filter for price? It sure looks like it. Let’s check out the site.
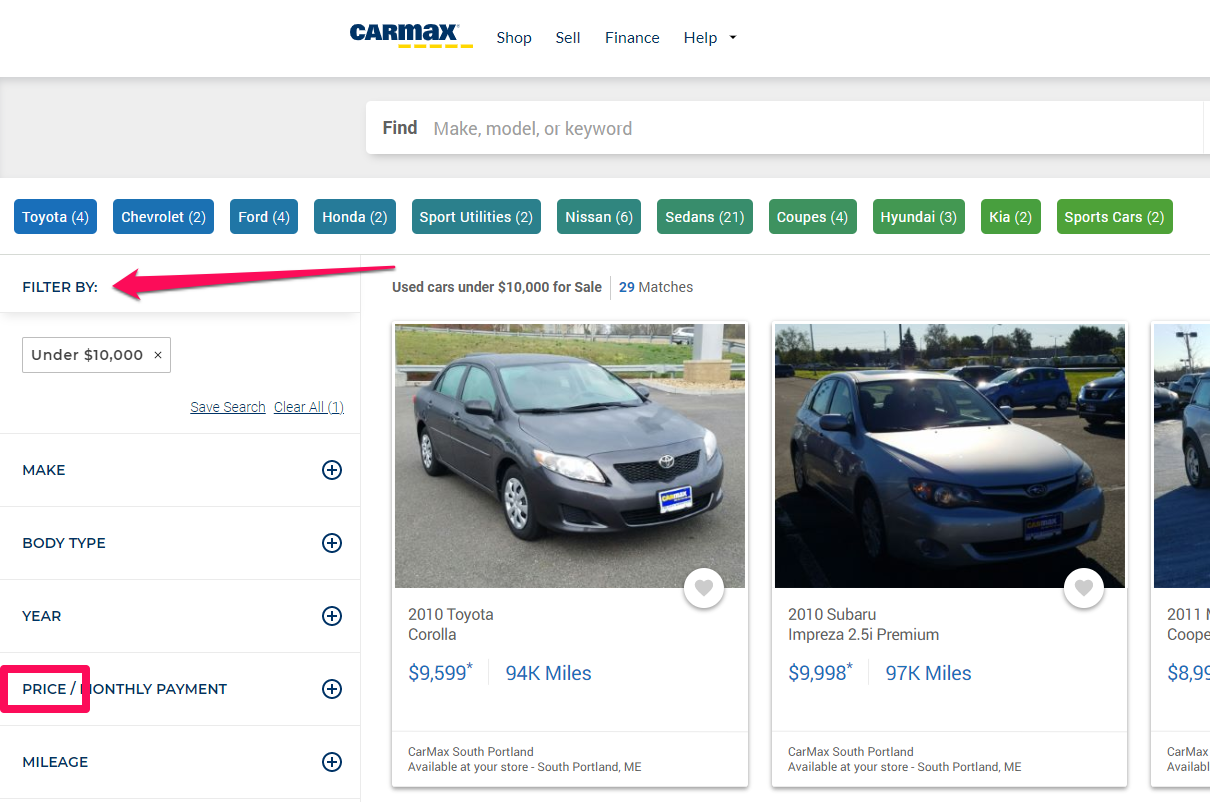
It’s seems they consider it a filter! Had Carmax taken the advice above and used a noindex tag on their price filters, they wouldn’t be ranking #1 right now and we would not have landed on their page.
Good thing they didn’t do that. Actually, Carmax does a pretty good job at telling Google which pages it actually wants indexed and which it doesn’t. We’ll use it more as an example.
So the difference between filters & facets is that facets are a result of filtering products. You use filters and they generate facets.
While the definition of facets in search is “sorting by multiple dimensions simultaneously”, which actually means using multiple filters, I like to define facets as the pages that result from filtering a search.
In my opinion, it’s not about having one filter or multiple filters. I can have a single filter: it will still create a facet. This way, it’s very easy to differentiate between them.
For example, I can apply a single sorting filter, by price, which will create a facet. The problem, however, is that the facet isn’t unique! And that’s when Google has a problem with it.
2. Faceted Search Problems & Challenges
Faceted navigation and search are great. They help you find exactly what you need pretty easily. In the following video you can see how you can take advantage of faceted search to filter out exactly the books you might want to read, from over hundreds of thousands of results to only 7.
Ideally, the site shouldn’t create these types of pages at all. Sure, we might think it’s mostly bad for search engines but useful for users.
However, search engines try to favor the user. If you think about it, how good would a user’s experience be if you kept showing them the same products every time they apply a new filter?
Or how good is it for them if no products are shown? For example, if you don’t have any products Size M, should you show that size as being available?
The problem with faceted navigation search is that it can cause duplicate content issues. And with facets, the number of pages grows exponentially.
Hypothetically, let’s say you have two filters in a book store:
- Fiction
- Historical
If we were to combine them, you’d probably say that there are 3 possible options:
- Only Fiction
- Only Historical
- Both Historical & Fiction
However, there is a 4th option: it’s Both Fiction & Historical.
So if you have 5 attributes (color, size, weight…), each containing about 5-10 variables (red, green, M, S, 10kg, 20kg…) you would have to multiply the variables to get the total amount of possible facets that can be generated.
If we have 15 colors, 10 sizes we already have 150 possible combinations. Add another 3 types of material and we end up with 450 combinations. Sort that by 8 different brands and we already have 3,600 products which is exactly the number of seconds there are in an hour… the Illuminati must be on me.
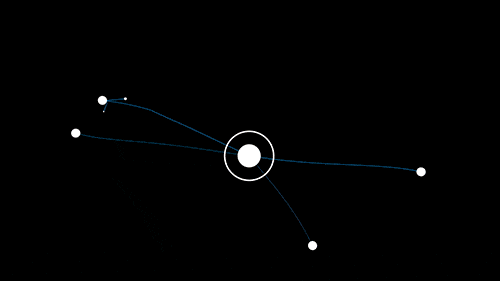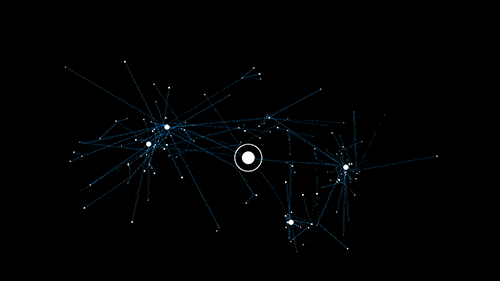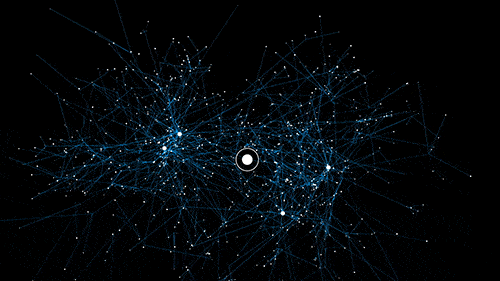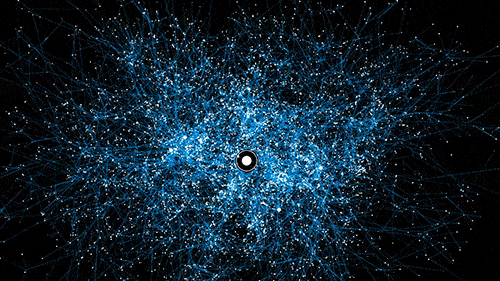
How fast facets can create duplicate content.
You get the point, too many filters, too many facets, too many URLs with duplicate content.
But aren’t those pages the same? I mean… both 1+2 and 2+1 equal 3, right? Well, while users might find those pages as being the same, search engines don’t! Why? Because of URLs.
3. How Google Handles URL Parameters & How It Affects SEO
Depending on which order the users choose to select the filters of a facet, some platforms generate different URLs for the same content. This is usually done using parameters.
Google treats URLs with parameters as separate pages, not an extension of the root URL, unless a canonical tag is specified.
So, in Google’s eyes, domain.com/books?filter=historical&fiction and domain.com/books?filter=fiction&historical are separate pages with duplicate content.
This is an issue because one of the pages doesn’t provide any extra value to the user.
Google doesn’t like duplicate content because it doesn’t provide much value to the users.
If you already have a page covering a set of products, why would you have a second page covering the exact same set? Why would Google want to display the exact same thing from the exact same website twice?
Sure, that happens, but Google is always trying to fix it. For example, Mihai Aperghis from Vertify notified John of some issues that kept appearing in the search results in Romania. After not much time, Dan Sullivan announced that they’re working on a diversity change. Sure, these two things might be unrelated, but it sure seems like a big coincidence.
There are ways to fix that. For example, you can use a canonical tag from one version to another to tell Google which is the original version that should be indexed and ranked. But Google sees canonical tags as recommendations, not as absolute rules, so it might ignore them!
However, there is another issue that content duplication creates, which won’t be fixed by adding canonical tags: Burning through Crawl Budget.

How facets can burn through & create a wasting of Crawl Budget.
When Google crawls your site, it allocates a certain budget for how many pages it will crawl, depending on certain factors, such as how popular your site is, how much traffic it gets how big it is and how relevant it is.
If you’re wasting that budget on pages that will anyway perform poorly because they don’t provide any value, important pages that are unique and relevant might not get crawled, losing the chance to rank higher.
That’s why it’s important to address these issues and make sure you don’t index irrelevant pages. But which parameters and facets should you index and which should you not? How do you deal with these problems? And why do some sites, like Amazon, index everything and do so well?
4. Which URL Parameters to Index & Which Ones to Not
Deciding which pages you should let Google index and which pages you shouldn’t is important for best SEO performance.
If you’re thinking about indexing ‘facets’ but not indexing ‘filters’ think again. Indexation has nothing to do with those things, but with search intent, volume and product supply.
World renowned SEO expert Aleyda Solis explains this very well in the following video of her SEO lessons series Crawling Mondays:
If your site has many pages, then you should only let Google index the ones that either:
- Have enough demand: These pages should actively target a specific keyword or set of keywords that has a search demand. If users don’t search for it or never reach that page through organic search (you don’t see any impressions or clicks for it in Google Search Console) then maybe it’s a better idea not to index them.
- Have enough supply: These pages should not result in empty pages. If you only have 1-2 products or none at all in the facet while other facets provide 10-20 results, then maybe it’s a better idea not to index it.
- Are unique in the most part: These pages should not be very similar. Sure, there will be similarities, but if applying a second or third filter only results in a 5-10% difference, then maybe it’s better to not index those pages. This usually is also related to supply. Not enough products might lead to duplicate results.
That’s exactly why Amazon is doing so well, even though they are indexing all their pages. It’s because they have such a big supply of products that most of their facets have enough uniqueness to not be considered duplicate.
Sure, some are probably identical but, for example, even after filtering by 7-8 different dimensions I still get about 7 results, which is great.
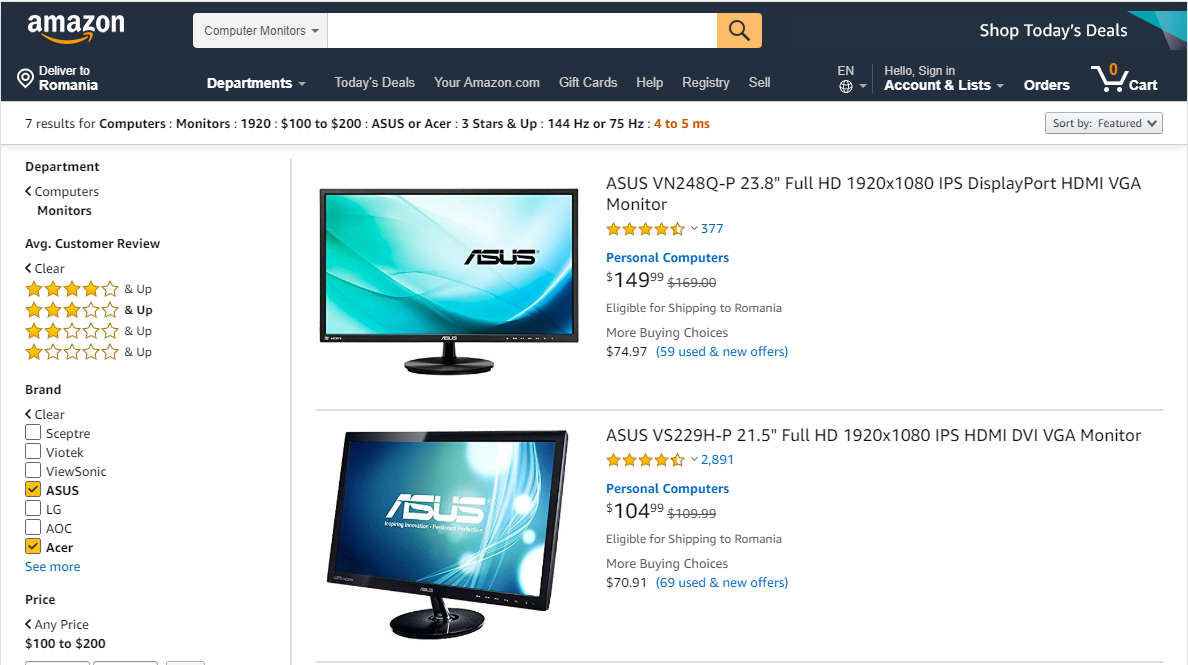
Amazon is also a very popular site with high amounts of traffic going to it each day, which means Google will allocate more crawl budget for it that it will allocate for a smaller eCommerce site.
But for smaller sites, this might not always be the case. So you want to follow the best practices for best results. Of course, strategies can be different from one ecommerce site to another.
5. How to Fix Faceted Search Issues & Have a Good Navigation Structure
Fixing a complex duplicate content issue might require both time and budget. It’s not easy to manage hundreds of thousands of pages so you can always look for tools or e-commerce agencies to help you out.
Here are Google’s official tips on faceted navigation pages. However, Google gives more specific examples on how things should look, but not on how to implement them.
There’s a very big difference between the effects of 301 redirects, canonical tags, noindexing and disallowing pages entirely in Robots.txt.
Unfortunately, I can’t tell you exactly how to implement things, because this can differ from one case to another. However, I can outline the best practices and give you a hint on how implementation could be done.
But the first thing you have to do is create a spreadsheet of your categories, subcategories and filters. Then you should do an extensive keyword research and map keyword clusters to the categories and filters.
Did You Know
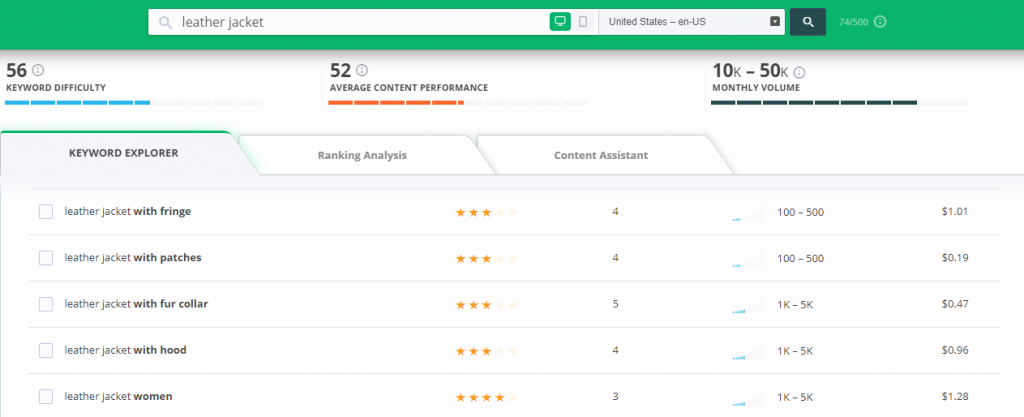
To have a general idea of which facets you should index and which not, you need to perform an in-depth keyword research. You can use tools like the CognitiveSEO Keyword Tool or even the Google Search Console to find keywords. Along with other keyword ideas, the tool will give you great keyword insights, such as the volume of the search, their relevancy, the cost per click, etc.
The quickest solution would be to not have any filters at all. Just use category pages with enough demand & supply. If you don’t have many products, not having filters might work for you. Simply create categories for the keywords that users search for and add products in multiple categories.
A nicely implemented example comes from FilmJackets, a site that sells leather jackets.
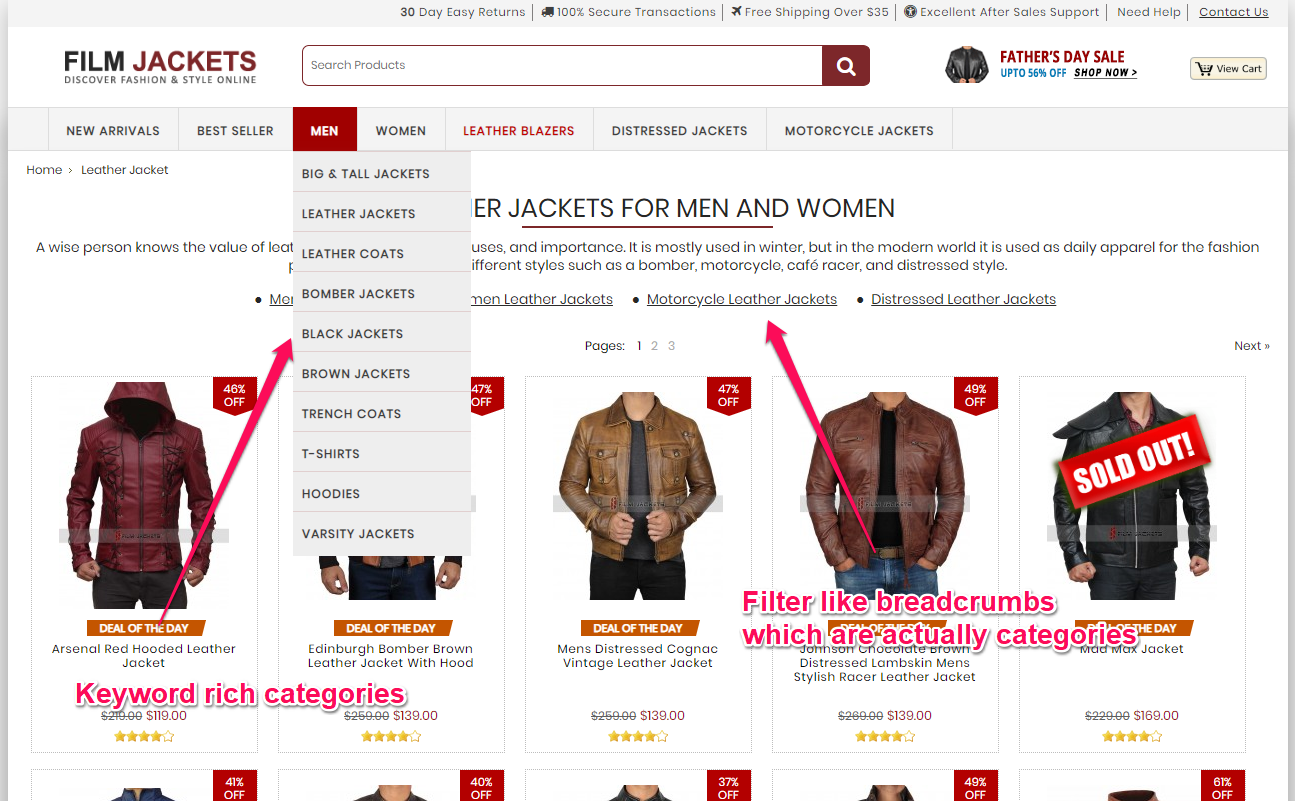
It only took me a couple of scrolls on a desktop to see all the jackets, although on a mobile device that might be harder. Anyway, the site’s design is visually oriented, which makes me want to see all the jackets to see which design I like.
However, if they had had a lot more products and a bigger variety (such as multiple materials), filters might have been useful. The user is also led to believe that the store has all the sizes and colors in stock, as that type of filtering is made on the product page, right before placing the order.
But overall, the user experience with the current amount of products should be good. It’s a simple solution for a smaller eCommerce website and it is elegantly implemented on this website.
If you’re a big site, then you have multiple options of dealing with the problem, depending on your platform’s possibilities. Serge Stefoglo from Distilled.net did a great post on Moz showcasing the effects of different methods that deal with/fix duplicate content.
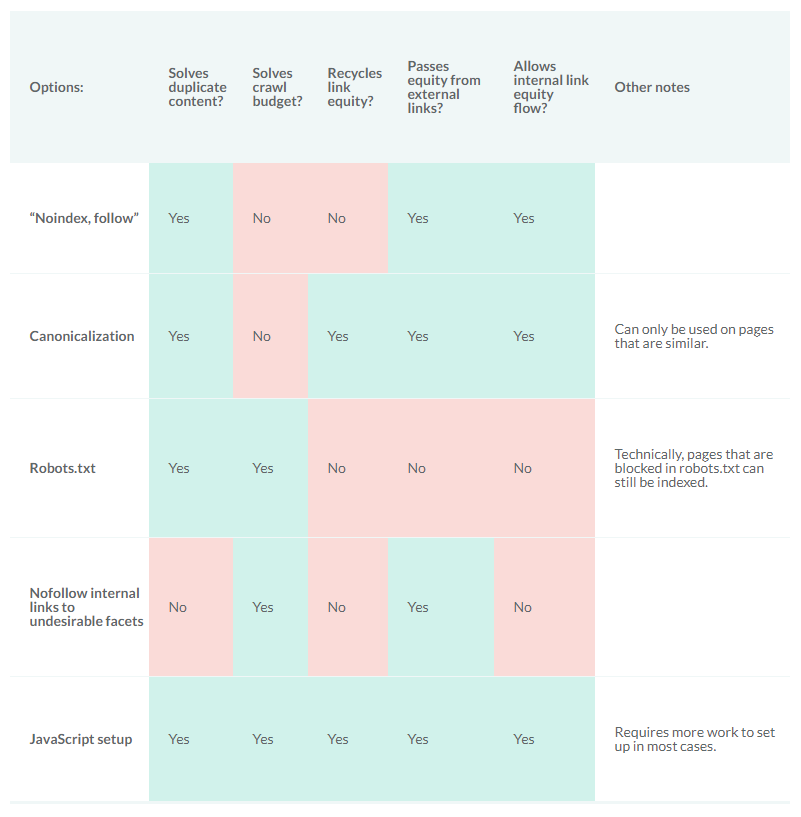
So, the best fix seems like a JavaScript setup. But what does that mean? And how can it be implemented? Well, this is up to your development team.
Eric Enge from StoneTemple tells us how Ajax and jQuery work together to fix faceted navigation duplicate content issues.
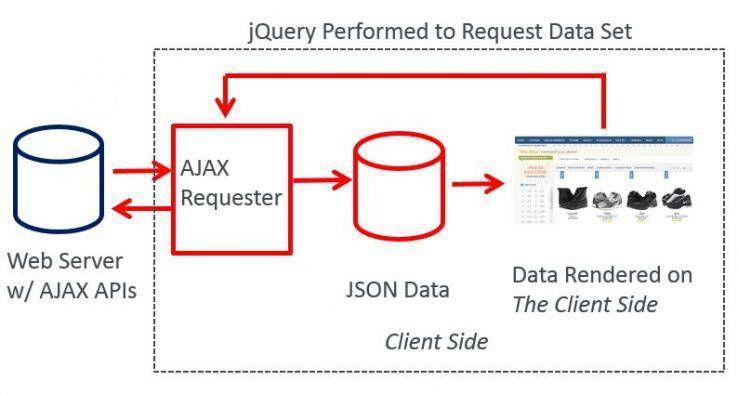
Carmax, our previous example, uses a similar JavaScript technique to generate its filtered pages. It’s not identical but it uses JavaScript to direct users to the facets. This means that Google won’t see those links when crawling the pages, so they can’t burn through crawl budget.
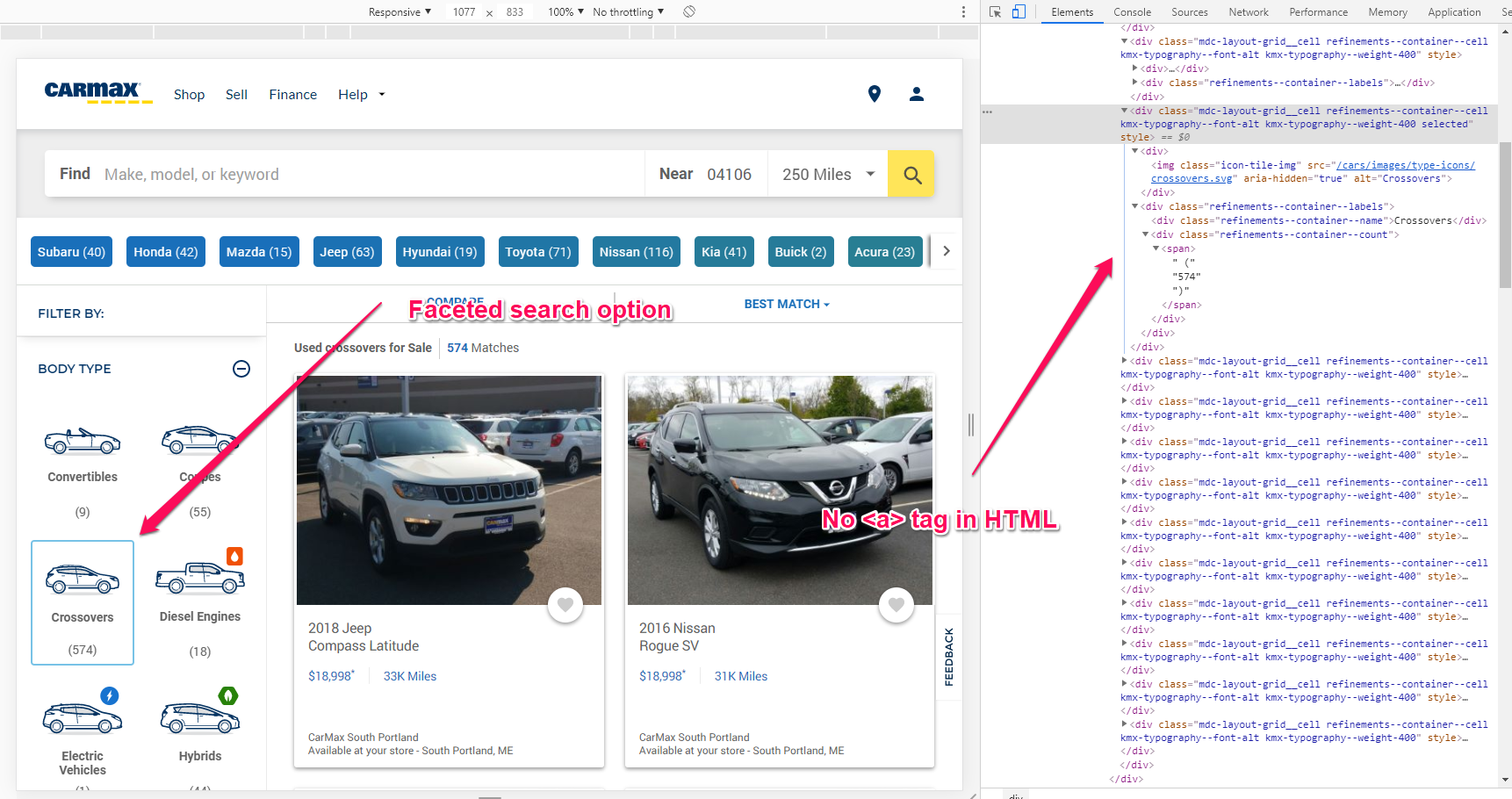
However, this can lead to another problem. Faceted pages can’t be found by search engines anymore! That’s because the JS doesn’t generate <a> tags in the HTML anymore, so Google’s crawler might have a hard time getting to the important pages.
When using AJAX and JavaScript for your facets, you have to make sure your important links can be easily crawled by Search Engines.
Carmax does this flawlessly, by stating its most important facets near the Homepage, at just 1 click away on their cars page. There are also some footer links to different locations on category or facet pages.
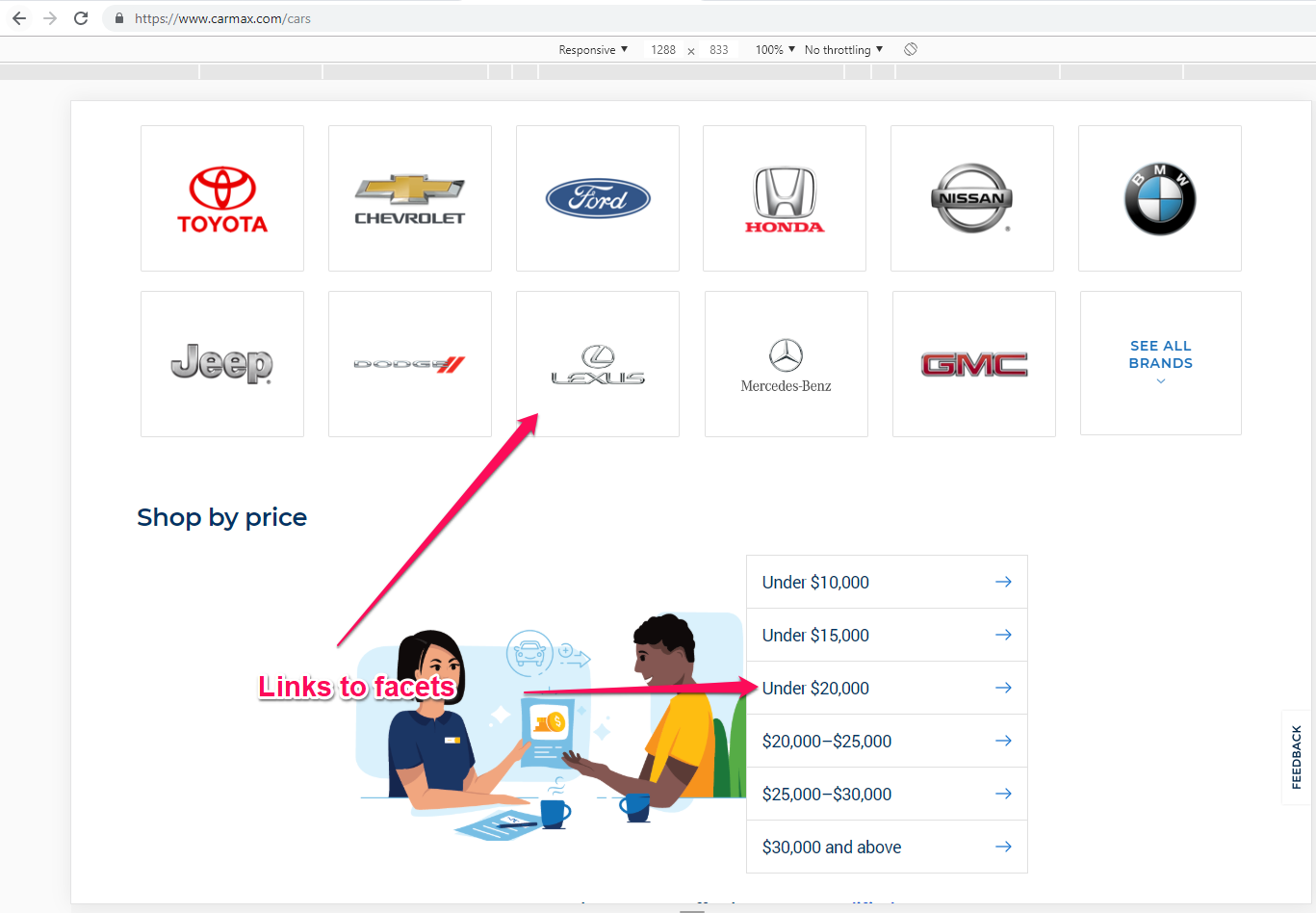
With this implementation, Google won’t have to crawl millions of possible combinations and it will still find the most important facets the site wants indexed. The same result can be obtained with a sitemap, but it’s better if you have a direct crawl path to them.
But what if someone links to those pages? Can they still get indexed? Yes. As long as they don’t have a noindex meta tag or are blocked in robots.txt, they can. But that’s not an issue because you can use canonical tags!
Pages can still get indexed if other websites link to them. Using canonical tags can help prevent duplicate content issues.
Carmax also takes advantage of canonical tags. For example, the page /cars?location=norcross+ga&price=10000 is canonicalized to /cars?price=10000&location=norcross+ga.
Ideally, the links should always be generated in the same order. For example, if I choose the order to be price, location, size, then even if the user selects location first and then price and size, the URL will still be generated in the initial order.
If you have a lot of pages, you want to focus on fixing the crawl budget issue. On the other side, if you have a lot of backlinks pointing to different filters of your pages, then you want to also pass link equity from external websites.
Start with canonical tags. These should be set up regardless if you then decide to index those pages or not.
Most pages should have a self referencing canonical, but if these pages are duplicate, then a canonical version is required.
Noindex and canonical tags will still be wasting your crawl budget, so if you can’t do a JavaScript implementation, you might want to block the pages from being crawled in robots.txt.
However, also take into account that using Robots.txt will dilute link equity, so make sure those pages don’t have internal links nor backlinks pointing to them.
A good way of doing this is by adding an extra parameter (noindex=1) to facets with more than 1 or 2 filters. Then you can add the following line:
|
1 |
Disallow: /*noindex=1 |
This way, any URL which contains the noindex=1 string will be blocked from crawling.
So for example, search by size will be:
- site.com/category?size=m
Search by color will be:
- site.com/category?color=black
Search by size and color will be:
- site.com/category?size=m&color=black&noindex=1
However, keep in mind the supply and demand rule, if there are searches for “black category size m” then maybe you should not block those pages!
If your pages are already indexed and you want them to not get indexed and not burn crawl budget, you’ll first have to set up a noindex meta tag on the page and then add the pages to robots.txt.
Since robots.txt block crawling altogether, there’s no way for the search engine crawler to see the noindex meta tag!
So first, make sure you let the search engine find those pages to see the noindex meta tag, and after they’re removed from the index, you can add them to the robots.txt file to prevent them from burning the crawl budget.
Conclusion
Hopefully, you now have a better idea on which pages in your faceted search navigation menu you should index and which ones you should not.
You can use a JavaScript setup to prevent the links from being created as long as you ensure the most important ones which have demand and supply can be found by search engines.
You can also use robots.txt to disallow crawlers from accessing those URLs, saving up crawl budget. However, keep in mind that if you have or get backlinks to those pages, they won’t help your site anymore!
What’s your experience with faceted navigation search? Do you use JavaScript or do you use a mix of canonical tags, noindex meta tags and robots.txt? Let us know in the comments section below.



Amazing, awesome job with this article including its visual components. Some very complex SEO concerns now make more sense. I have recently run into a similar issue with a client whose offerings now include combo packages of existing, extremely well-ranked products, so additionally this content is very timely on my side.